
David G. Simmons
vrijdag 23 juni 2017
Je hebt niet gezien Big Data Toch
Ja, ik weet het, “Big Data” als een buzz-woord is zo 5 minuten geleden. De tech wereld is chronisch ADD en gevoelig voor afgeleid te worden door de volgende glimmende object (OOh! Kijk, ivd !, Wacht, AI! EEKHOORN !!) Maar verblijf met me op dit punt. Het is allemaal met elkaar verbonden. Ik heb gezegd ten minste sinds 2005 (toen Big Data was al de woede) dat je niet echt big data hebben gezien tot het internet van de dingen echt op gang komt in volle kracht. Social media is vrij productief - een gemiddelde van 6.000 tweets per seconde, of een half miljard tweets per dag. Dat is een grote hoeveelheid gegevens. Maar het is peanuts. Laten we zeggen dat je een industriële IoT inzet monitoren van 1.000 machines. Elke machine is het verschaffen van telemetrie on 7 of 8 parameters. Het is logging dat telemetrie 2 - 3 keer per seconde. Dat is 16.000 per seconde. Van ONE fabriek. Laten we nu zeggen dat je 10 fabrieken wereldwijd. 160.000 per seconde. Proberen te houden. Nee, echt, gewoon proberen.
Hier is mijn ivd Rule, nogmaals: iets dat is gebaseerd op het aantal mensen op de planeet is bovenste grenzen beperkt. Toen ik voor het eerst zei dit in 2004 zon (een moment van stilte, aub) licentie had Java op 1 miljard mobiele telefoons. Zelfs als ieder mens uitgevoerd 4 mobiele telefoons, die zou hebben slechts 24 miljard apparaten (; y 6 miljard bevolking op dat moment was een) geweest. Een beperkt markt.
Ivd is niet gebaseerd op het aantal mensen op de planeet, maar op het aantaldingen en is dus niet per se upper-begrensd. Denken dat - geen bovengrens - zoals dit geldt voor de inrichtingen en dus de gegevensstroom. Nu is de belofte van ivd-systemen is om real-time te bieden, bruikbare gegevens. En echt, waarom zou je naar de tijd en de kosten van de inzet van een ivd-systeem als je niet van plan om iets te doen met de stortvloed van gegevens zal verstrekken. Zelfs beter dan alleen het bieden van bruikbare gegevens verstrekt ** real-time ** bruikbare informatie.
Het probleem is duidelijk, hoe doe je eigenlijk een soort van redelijke data-analyse op 160.000 datapunten per seconde? Dat is 9,6 miljoen per minuut. Dat is een half miljard per uur. Dus dat is het hele Twitter-feed per dag elk uur. Elk. Uur.
Op dit moment, dit is niet iets dat de meeste mensen in het Internet of Things wereld aanpakken, of zelfs over. Waarom? Omdat, natuurlijk, ze geen oplossing voor hebben. Kijken! EEKHOORN! We zullen gewoon niet over praten.
Maar ik struikelde op iets. Iets heel pretty amazing. Iets dat eigenlijk dit probleem oplost in de meest elegante manier. Wat als je kon moeiteloos query en visualiseren van een dataset van miljarden rijen met gegevens? Live. Het heet MAPD. Het is een database die draait op GPU’s, niet CPU (hoewel je het kan draaien op CPU’s als u tragere prestaties wilt). GPU’s doen echt echt goed bij parallelizing gegevensverwerking, en natuurlijk graphics.
Dus laten we gewoon kijken naar een van hun demo. Het is de scheepsbewegingen in de VS tussen 2009 en 2015. Allemaal. Elke. Meer dan 11 miljard verslagen van ruimtelijke data.
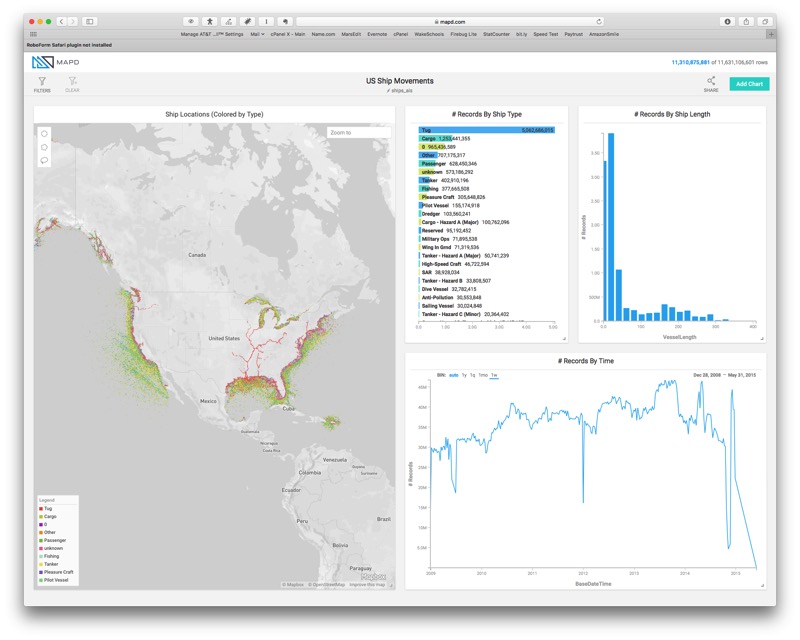
Dat is nog een schot, maar als je gaan spelen met de demo zul je merken dat je naar beneden kunt boren door de gegevens. Way naar beneden in de gegevens. Mijn beste vriend is een sleepboot kapitein. Hij heeft gewerkt aan de nieuwe Tapanzee Bridge voor de laatste 5 jaar. Dus besloot ik om te zien wat ik kon zien wat er gaande was daar.
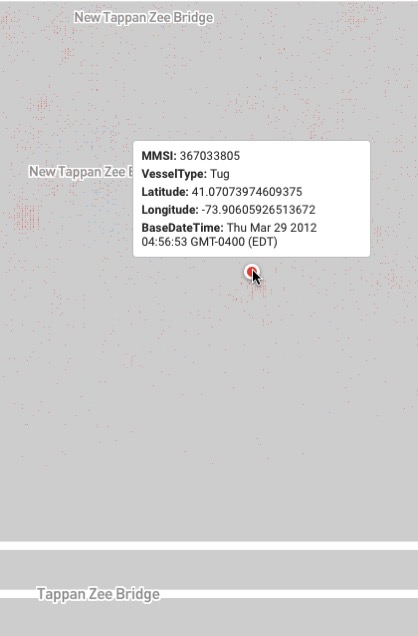
Ik vond zijn sleepboot. Ik vond ook zijn sleepboot en de rechtshandhaving boten, ’s nachts iemand sprong van de brug en ze rende naar ze te vinden. En het is een naadloze, vloeiende, meeslepende ervaring.
Absoluut ongelofelijk! Nu, als ze dat kunnen doen met 11 miljard geospatiale gegevens van schepen, wel, dan is dat niet te ver af van een dag ter waarde van gegevens in mijn bovenstaande voorbeelden. Dat kunt u uw binnenkomende gegevens daadwerkelijk te visualiseren in real time, en maken het actiegericht. Dat maakt het internet der dingen eigenlijk praktisch en nuttig. Tenslotte!