
David G. Simmons
maandag 18 december 2017
Bouwen aan een IoT Gateway Device voor de lokale Alerting en Data Downsampling
Er zijn allerlei manieren om architect uw ivd Deployment, en wat goed is voor een onderneming zal niet noodzakelijkerwijs gelijk te hebben voor een ander. Afhankelijk van de grootte en complexiteit van uw ivd project, kan er natuurlijk veel componenten. Een van de meer algemene architectuur is sensor hubs of gateway inrichtingen voor het verzamelen van gegevens vanuit een aantal sensor nodes en dan naar voren te implementeren die gegevens aan een stroomopwaarts gegevensverzameling voor de onderneming. Deze gateway of hub apparaten meestal toestaan dat een Z-Wave-apparaat om verbinding met het internet voor het uploaden van gegevens, of brug tussen Bluetooth-apparaten met een WiFi of andere netwerkverbinding.
Bovendien zijn de meeste van deze gateway of hub-apparaten hebben de neiging om ‘domme’ gateways zijn. Ze doen niets anders dan naar voren gegevens te doen op een upstream verzamelaar. Maar wat als het Internet of Things Gateway kan een smart device zijn? Wat als je zou kunnen doen lokale analyse en verwerking van gegevens op de naaf apparaat voor verzenden van de gegevens aan de hand? Zou dat niet nuttig zijn!
Het bouwen van een Gateway
Ik besloot om te bouwen (een andere) IoT Smart Gateway-apparaat vanmorgen. Ik heb (soort van) [gebouwd één voor] (/ berichten / category / iot / iot-hardware / running-influxdb-on-an-artik-520 /) in de vorm van een ARTIK-520 loopt InfluxDB. Maar een ARTIK-520 is niet de goedkoopste ding die er zijn, en wanneer je ivd-apparaten aan het bouwen bent, soms goedkoper is beter. Niet altijd, maar als je veel en veel bouwen van gateways, je liever niet breken de bank op hen. Ik groef mijn [Pine-64] box (https://www.pine64.org) dat ik een paar jaar geleden gekocht en kreeg aan het werk. Waarom Pine-64 en niet Raspberry Pi? Nou, het Pine-64 is ongeveer 1/2 van de kosten. Ja, 1/2 van de kosten. Het is $ 15 in plaats van $ 35, dus er is dat. Het heeft precies dezelfde ARM A53 quad-core 1,2 GHz processor - mijn heeft 2 GB geheugen, ten opzichte van de 1 GB op een RPI - en het heeft een meer krachtige GPU, als je in dat soort dingen. Het kwam ook met ingebouwde WiFi, dus geen dongle, en ik kreeg de Z-Wave optionele boord, zodat ik aan sub-GHz IoT apparaten kunnen praten.
Een van de leuke dingen over het uitvoeren van dit soort apparaten ivd Gateways is dat je alleen in je opslag worden beperkt door de grootte van de microSD-kaart die u gebruikt. Ik ben alleen met behulp van een 16 GB-kaart, maar de Pine-64 kan tot een 256 GB-kaart.
Wat is er nodig om de teek stack up and running op een Pine-64? Niet verrassend, de Time To Awesome ™ is echt kort! Zodra u uw Pine-64 doos up and running - Ik stel voor het gebruik van de Xenial beeld, want het is het beeld ‘officiële’ Pine-64 en het is Ubuntu, dus het is super makkelijk met InfluxDB. Vergeet niet om te draaien
apt-get upgrade
Zodra je het hebt up and running om ervoor te zorgen dat je alles up-to-date.
Voeg vervolgens de instroom repositories om apt-get:
curl -sL https://repos.influxdata.com/influxdb.key | apt-key add -
source /etc/lsb-release
echo "deb https://repos.influxdata.com/${DISTRIB_ID,,} ${DISTRIB_CODENAME} stable" | tee -a /etc/apt/sources.list
U zult waarschijnlijk moeten mensen met sudo lopen, maar ik bedriegen en run ‘sudo bash’ om mee te beginnen en dan ben ik klaar.
Vervolgens moet u een pakket dat ontbreekt toevoegen - en vereist - om de toegang van de InfluxData repositories:
apt-get install apt-transport-https
Dan is het gewoon een kwestie van
apt-get install influxdb chronograf telegraf kapacitor
en je bent klaar om te gaan!
Load Testing Device
Besloot ik dat het misschien een goed idee om een belasting te houden met dit kleine apparaat gewoon om te zien wat het in staat de behandeling was, dus ik ‘instroom stress’ gedownload van [GitHub] (https://github.com/influxdata/influx -stress) en liep het tegen dit apparaat.
Using batch size of 10000 line(s)
Spreading writes across 100000 series
Throttling output to ~200000 points/sec
Using 20 concurrent writer(s)
Running until ~18446744073709551615 points sent or until ~2562047h47m16.854775807s has elapsed
Wow … dat is 200.000 punten per seconde! Dat moet een aantal ernstige nadruk te leggen op mijn kleine Pine-64! En het blijkt dat het soort deed:
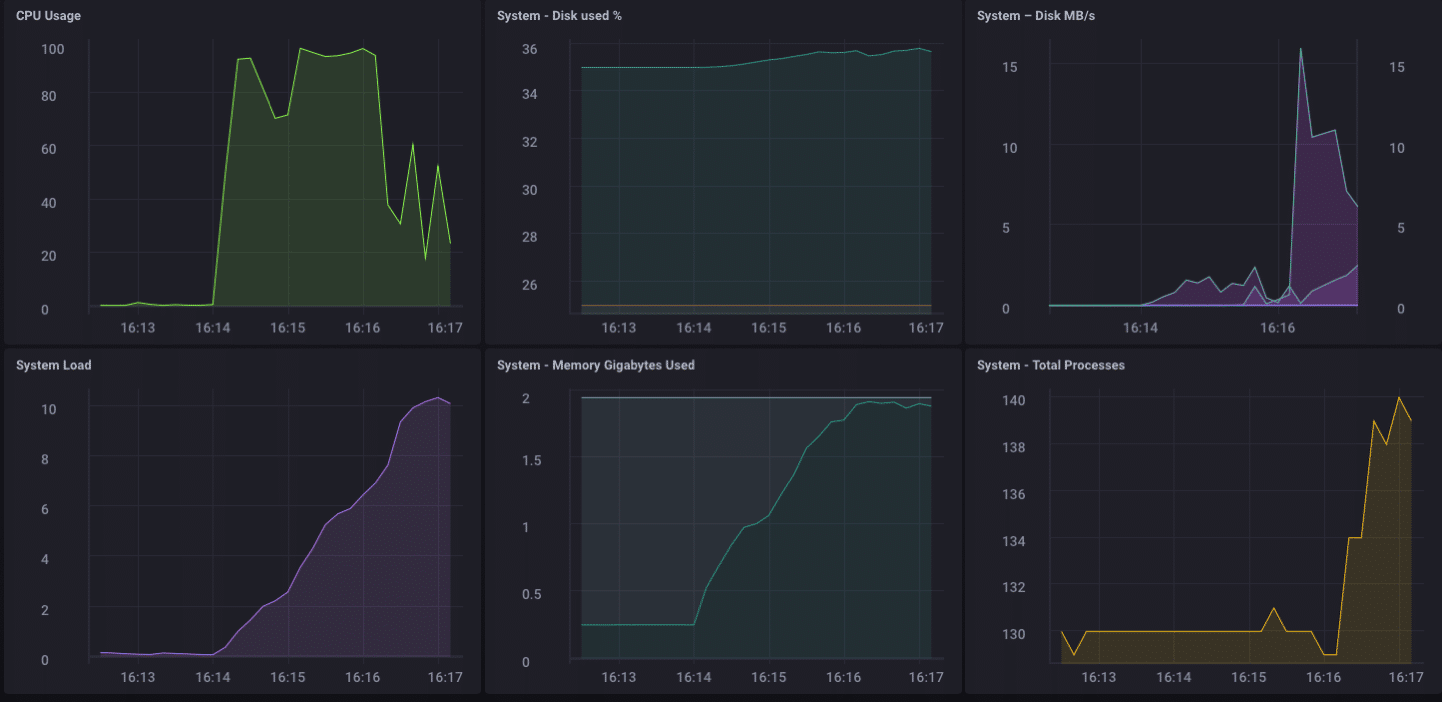
Zoals u kunt zien, is het vrij snel bijgevuld uit de 2 GB geheugen, en gekoppeld aan de CPU op 100%. Maar als een gateway-apparaat, het is onwaarschijnlijk, in het echte leven, om een dergelijke belasting te zien. Ik denk dat, in termen van het gebruik van real-life als een gateway, zou ik goed binnen mijn bereik zijn als ik alleen was het verzamelen van enkele tientallen tot misschien een honderdtal sensoren.
Local Analytics
Zoals je hierboven kunt zien op het dashboard, kan ik gemakkelijk doen sommige lokale analytics op het Pine-64. Het heeft een ingebouwde HDMI-interface, en een volledige GPU, dus waardoor de lokale toegang tot het dashboard voor het bewaken is doodsimpel. Maar zoals ik al eerder zei, zou het veel nuttiger zijn als het apparaat meer dan dat kon doen. Het is onwaarschijnlijk dat, in de echte wereld, je gaat om al uw gegevens te verzamelen over een gateway-apparaat en al uw analytics, etc. daar. Dat is niet wat gateways / hubs voor zijn.Sommige lokale analytics, waarschuwen, enz. Zou goed zijn - verplaats enkele van de verwerking van uit de richting van de rand als je kunt - maar toch wilt doorsturen data upstream.
Downsampling de Data
Het is vrij gemakkelijk om gewoon een gateway-apparaat gebruiken om te sturen al uw gegevens stroomopwaarts, maar als je te maken hebt met problemen met de netwerkverbinding, en je probeert om geld of bandbreedte, of beide te slaan, ga je wilt een aantal gegevens downsampling doen voordat u uw gegevens doorsturen. Gelukkig is dit ook echt makkelijk te doen! Een gateway device lokale analyses kunnen doen verwerken aantal lokale waarschuwingen, en kunnen de gegevens ook downsamplen voordat deze stroomopwaarts enorm nuttig in ivd. Het is ook vrij eenvoudig te doen!
Laten we eerst het opzetten van onze gateway-apparaat te kunnen sturen gegevens stroomopwaarts naar een ander exemplaar van InfluxDB. Er zijn verschillende manieren om dit te doen, maar omdat we gaan doen sommige gegevens downsampling via Kapacitor, doen we het via de kapacitor.conf bestand. De kapacitor.conf bestand heeft al een sectie met een [[influxdb]] vermelding voor ’localhost’ dus we moeten een nieuwe [influxdb] [] sectie toe te voegen voor de upstream bijvoorbeeld:
[[influxdb]]
enabled = true
name = "mycluster"
default = false
urls = ["http://192.168.1.121:8086"]
username = ""
password = ""
ssl-ca = ""
ssl-cert = ""
ssl-key = ""
insecure-skip-verify = false
timeout = "0s"
disable-subscriptions = false
subscription-protocol = "http"
subscription-mode = "cluster"
kapacitor-hostname = ""
http-port = 0
udp-bind = ""
udp-buffer = 1000
udp-read-buffer = 0
startup-timeout = "5m0s"
subscriptions-sync-interval = "1m0s"
[influxdb.excluded-subscriptions]
_kapacitor = ["autogen"]
Dat lost een deel van het probleem. Nu moeten we eigenlijk Verkleinen van de gegevens, en stuur het op. Sinds ik ben met behulp van Chronograf v1.3.10, ik heb een ingebouwde TICKscript editor, dus ik ga naar de ‘Alerting’ Tab in Chronograf, en maak een nieuwe TIK Script, en selecteer de telegraf.autoget database mijn bron :
Ik ben niet echt te verzamelen Sensor gegevens op dit apparaat nog niet, dus ik het CPU-gebruik zullen gebruiken als mijn gegevens, en ik zal het downsamplen in mijn TICKScript. Ik heb een zeer fundamentele TICKScript geschreven om mijn CPU data downsample en doorsturen stroomopwaarts:
stream
|from()
.database('telegraf')
.measurement('cpu')
.groupBy(*)
|where(lambda: isPresent("usage_system"))
|window()
.period(1m)
.every(1m)
.align()
|mean('usage_system')
.as('mean_usage_system')
|influxDBOut()
.cluster('mycluster')
.create()
.database('downsample')
.retentionPolicy('autogen')
.measurement('mean_cpu_idle')
.precision('s')
Dat script neemt gewoon de usage_system gebied van de CPU meting elke minuut, berekent het gemiddelde, en schrijft die waarde stroomopwaarts naar mijn upstream InfluxDB instantie. Op de gateway-apparaat, de CPU data ziet er als volgt uit:
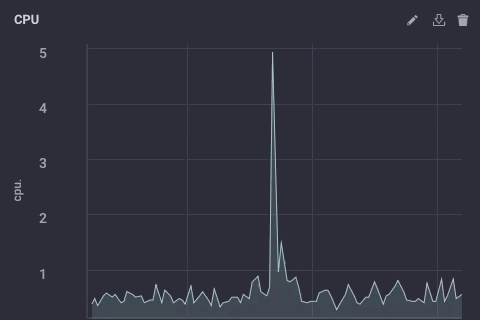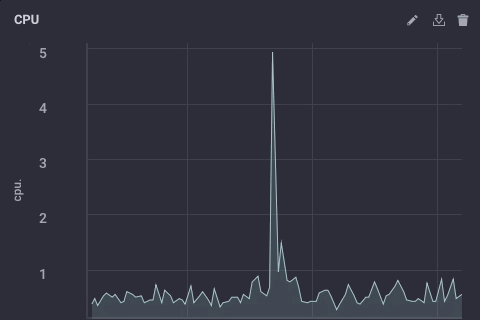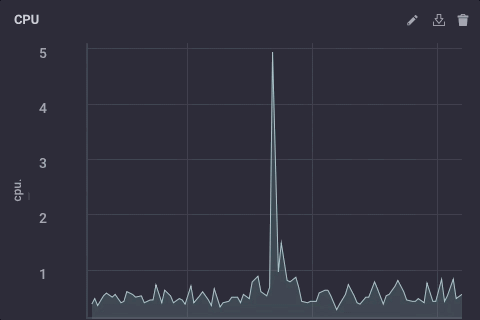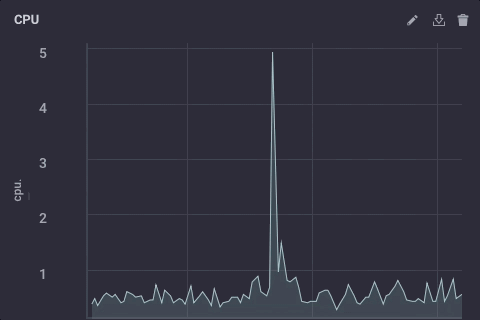
De gedownsampled gegevens op mijn upstream bijvoorbeeld ziet er als volgt:
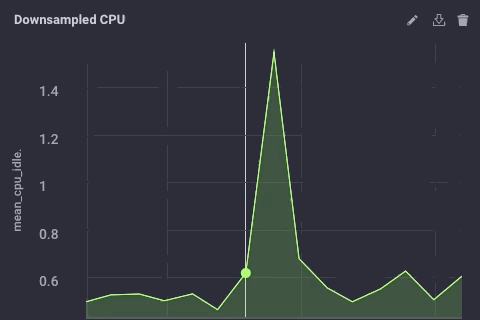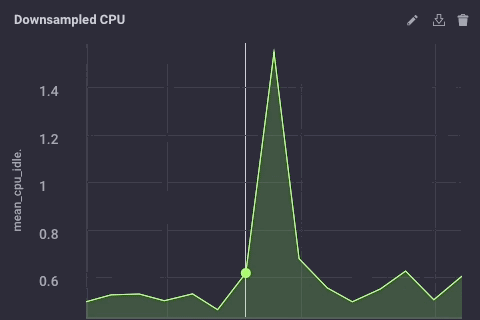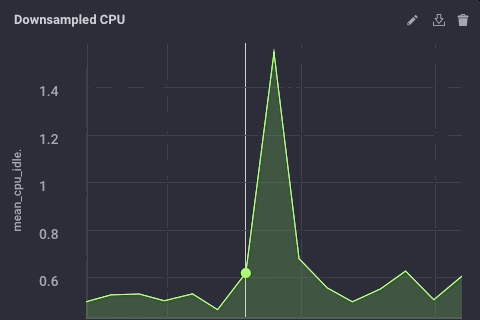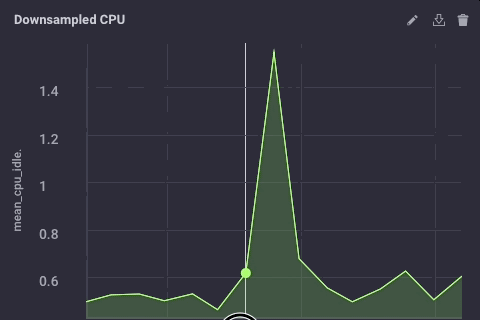
Het is dezelfde gegevens, maar veel minder korrelig. Tot slot ga ik stel het bewaren van gegevens beleid op mijn gateway apparaat om slechts 1 dag, dus ik weet niet het apparaat te vullen, maar ik kan nog steeds een beetje geschiedenis lokaal:
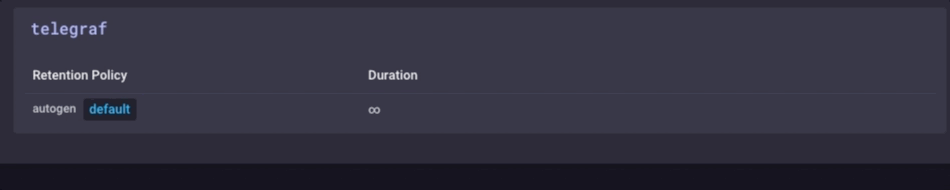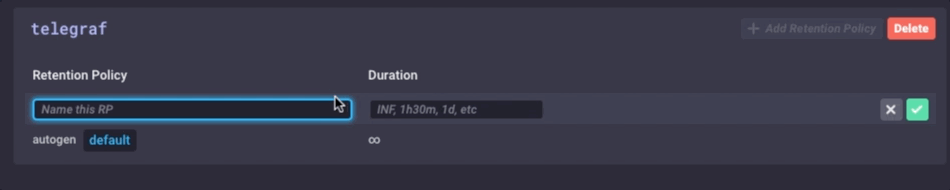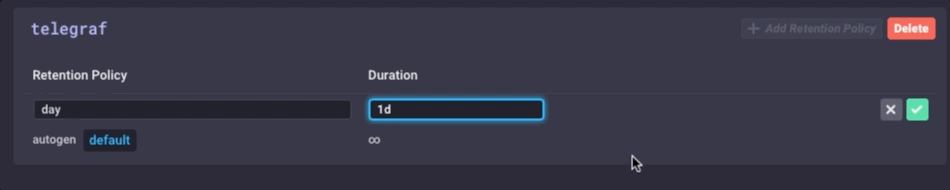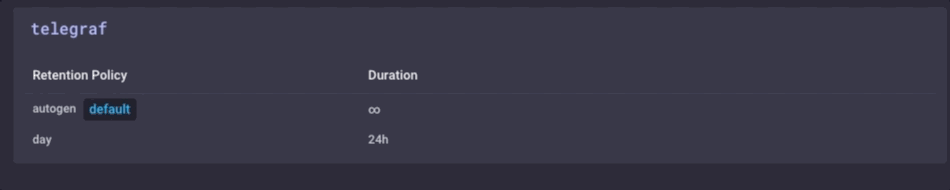
Ik heb nu een ivd Gateway-apparaat dat de lokale sensor data kan verzamelen, presenteren een aantal analyses om een lokale gebruiker, doen sommige lokale alarmering (zodra ik het opzetten van een aantal kapacitor waarschuwingen) en vervolgens Verkleinen van de lokale gegevens en stuur het upstream mijn enterprise InfluxDB bijvoorbeeld voor verdere analyse en verwerking. Ik kan het sterk granulaire milliseconde gegevens beschikbaar over het gateway-apparaat, en de minder korrelige 1 minuut gegevens op mijn upstream apparaat waardoor ik nog steeds inzicht in de lokale sensoren zonder de bandbreedte kosten voor verzenden van alle gegevens te betalen stroomopwaarts.
Ik kan ook deze werkwijze verdere keten de data opslag door het opslaan van de 1-minuut data op regionaal InfluxDB bijvoorbeeld omleiden verdere lager bemonsterde gegevens van een InfluxDB geval waarin ik sensorgegevens kunnen aggregeren afkomstig mijn gehele onderneming.
I zou gewoon alle gegevens in de keten te sturen naar mijn ultieme enterprise data-aggregator, maar als ik het aggregeren van tienduizenden sensoren en hun gegevens, de opslag en bandbreedte kosten kunnen beginnen met het nut van de hooggeschoolde opwegen tegen korrelige aard van de gegevens.
Conclusie
Ik herhaal dit zo vaak ik zou kunnen hebben om het te hebben getatoeëerd op mijn voorhoofd, maar ik zeg het nogmaals: ivd Data is eigenlijk alleen nuttig als het tijdig, accuraat, en *** bruikbare **. * Hoe ouder uw gegevens, hoe minder bruikbare het wordt. Hoe minder actiegericht is, hoe minder details die u nodig hebt. Downsampling uw gegevens, en stellen steeds langer bewaren van gegevens beleid als je gaat, kan ervoor zorgen dat uw zeer directe data heeft de specificiteit zeer bruikbare en zeer nauwkeurig te zijn, met behoud van de lange termijn trends in uw gegevens voor de langere termijn trend analyse.