



David G. Simmons
June 25, 2020
Wat gebeurt er als je je SQL-database op het internet
En dan geplaatst we het naar Hacker News.
Als je luistert naar, nou ja, vrijwel iedereen rationeel, zij zullen u vertellen in niet mis te verstane termen dat het laatste wat je ooit wilt doen is zet je SQL-database op het internet. En zelfs als je gek genoeg om dat te doen, je zeker zou nooit gaan posten het adres om het op een plek als Hacker News. Niet tenzij je een masochist toch.
We deden het al, en we zijn niet zelfs een beetje spijt van.
Het idee
[QuestDB] (https://questdb.io/?ref=davidgsiot) heeft opgebouwd wat we denken is de snelste Open Source SQL-database in het bestaan. We hebben echt te doen. En we zijn behoorlijk trots op, in feite. Zozeer zelfs, dat we wilden iedereen die de kans een kans om het te nemen voor een spin wilde geven. Met echte data. Doen echte queries. Bijna iedereen kan trekken samen een demonstratie die presteert goed onder de juiste omstandigheden, waarbij alle parameters streng gecontroleerd.
Maar wat gebeurt er als je de hordes erop los te laten? Wat gebeurt er als je iemand run queries te laten tegen het? Nou, we kunnen je vertellen, nu.
Wat het is
Ten eerste, het is een SQL gebaseerde Time Series database, opgebouwd vanaf de grond opgebouwd voor de prestaties. Het is gebouwd om zeer grote hoeveelheden gegevens zeer snel op te slaan en query.
We ingezet het op een AWS c5.metal server in de London, UK datacenter (sorry alles wat je Noord-Amerikanen, is er een aantal ingebouwde vertraging te wijten aan de wetten van de fysica). Het werd geconfigureerd met 196GB RAM-geheugen, maar we waren alleen met behulp van 40GB op de piek gebruik. De c5.metal instantie biedt 2 24-core CPU (48 kernen), maar we gebruikten een van hen (24 cores) met 23 draden. We waren echt niet met behulp van overaldicht om het volledige potentieel van deze AWS instantie. Dat leek niet uit te maken op alle.
De data wordt opgeslagen op een volume AWS EBS die SSD toegang tot de gegevens verschaft. Het is niet allemaal in het geheugen.
De data is de volledige NYC Taxi Database plus bijbehorende weergegevens. Het komt neer op 1,6 miljard platen, met een gewicht van ongeveer 350GB aan data. Dat is een hoop. En het is te veel om op te slaan in het geheugen. Het is te veel om te cache.
We enkele klikbare vragen mensen begonnen te krijgen (geen van de resultaten werden de cache of vooraf berekend), maar we in wezen niet het soort vragen te beperken die gebruikers kunnen uitvoeren. We wilden zien, en laat gebruikers zien, hoe goed uitgevoerd op wat vraagt ze gooiden in.
Het was niet teleur!
The Hacker Nieuws Post
Een paar weken geleden schreven we over hoe we geïmplementeerd SIMD instructies om een miljard rijen aggregeren in milliseconden [1], dankzij een groot deel aan Agner Fog’s VCL bibliotheek [2]. Hoewel de aanvankelijke uitsluitend werd table gehele aggregaten in een unieke schaalwaarde, dit was een eerste stap zeer veelbelovende resultaten complexere aggregaties. Met de nieuwste versie van QuestDB, breiden we dit niveau van de prestaties te toetsen op basis van aggregaties. Om dit te doen, we geïmplementeerd Google’s snel hash table aka “Swisstable” [3], die kan worden gevonden in de Abseil bibliotheek [4]. In alle bescheidenheid, vonden we ook ruimte om iets te versnellen het voor onze use case. Onze versie van Swisstable is genaamd “rösti”, na de traditionele Zwitserse gerecht [5]. Er werden ook een aantal verbeteringen dankzij technieken door de gemeenschap voorgesteld zoals prefetch (die interessant bleek geen effect in kaart code zelf hebben) [6]. Naast C ++, gebruikten we onze eigen wachtrij systeem geschreven in Java met de uitvoering [7] parallelise. De resultaten zijn opmerkelijk: milliseconde latency op ingetoetste combinaties waarin overspanning over miljarden rijen. We dachten dat het zou een goede gelegenheid om onze vooruitgang door het maken van deze nieuwste release beschikbaar om online te proberen met een vooraf geladen dataset te tonen. Het draait op een AWS bijvoorbeeld met 23 draden. De gegevens worden opgeslagen op de harde schijf en omvat een 1.6billion rij NYC taxi dataset, 10 jaar van de gegevens over het weer met ongeveer 30 minuten resolutie en wekelijkse gasprijzen in het afgelopen decennium. Het exemplaar is gevestigd in Londen, zodat mensen buiten Europa verschillende netwerk vertragingen kunnen ervaren. De server-side tijd wordt gerapporteerd als “Execute”. Wij bieden monster queries aan de slag, maar je wordt aangemoedigd om ze te wijzigen. Houd er echter rekening mee dat niet elk type query is snel nog niet. Sommige zijn nog steeds actief onder een oude single-threaded model. Als u een van deze te vinden, dan weet je: het zal minuten in plaats van milliseconden duren. Maar beer met ons, dit is slechts een kwestie van tijd voordat we deze onmiddellijk te maken ook. Next in ons vizier is het tijd-bucket aggregaties met behulp van het monster door clausule. Als u geïnteresseerd bent in het controleren van de manier waarop we dit deden, onze code is beschikbaar in de open-source [8]. We kijken uit naar uw feedback over ons werk tot nu toe. Nog beter, zouden we graag meer ideeën om prestaties verder te verbeteren horen. Zelfs na tientallen jaren in high performance computing, zijn we nog steeds leren elke dag iets nieuws. [1]https://questdb.io/blog/2020/04/02/using-simd-to-aggregate-b?ref=davidgsiot [2]https://www.agner.org/optimize/vectorclass.pdf [3]https://www.youtube.com/watch?v=ncHmEUmJZf4 [4]https://github.com/abseil/abseil-cpp [5]https://github.com/questdb/questdb/blob/master/core/src/main [6]https://github.com/questdb/questdb/blob/master/core/src/main [7]https://questdb.io/blog/2020/03/15/interthread?ref=questdb [8]https://github.com/questdb/questdb
En dan geplaatst we de link naar de live-database.
En leunde achterover.
En keek naar de inkomend verkeer.
En probeerde niet in paniek te raken.
Wat is er gebeurd
Ten eerste, hebben we de voorpagina van Hacker News. Toen we er verbleven. Urenlang*.
We zagen veel verkeer. Ik bedoel eenlot van het verkeer. Ergens meer dan 20.000 unieke IP-adressen.
Exclusief eenvoudige show queries, zagen we 17.128 SQL-query’s met 2.485 syntax fouten in de queries. We teruggestuurd bijna 40GB aan data in antwoord op de vragen. De reactietijden waren fenomenaal. Sub-tweede antwoorden op bijna alle van de vragen.
Iemand in de HN opmerkingen gesuggereerd dat kolom winkels zijn slecht sluit zich aan, wat leidde tot iemand komen en proberen om de tafel zitten om zichzelf. Normaal gesproken zou dit een verbluffend slechte beslissing zijn.
Het resultaat was … niet wat ze verwachtten:
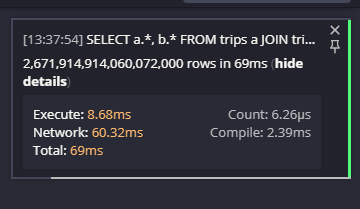
Ja, dat is 2.671.914.914.060.072.000 rijen. In 69ms (netwerk overdracht tijd). Dat is een hoop van de resultaten in een zeer korte tijd. Zeker niet wat ze verwachtten.
We zagen slechts een paar slechte acteurs proberen iets leuk:
2020-06-23T20:59:02.958813Z I i.q.c.h.p.JsonQueryProcessorState [8536] exec [q='drop table trips']
2020-06-24T02:56:55.782072Z I i.q.c.h.p.JsonQueryProcessorState [6318] exec [q='drop *']
Maar die werkte niet. We kunnen wel gek zijn, maar we zijn niet naïef.
Wat we geleerd
Het blijkt dat wanneer je iets doen als dit, leer je veel. Je leert over uw sterke en uw zwakke punten. En je leert over wat gebruikers willen doen met uw product en wat ze zullen doen om te proberen om het te breken.
Deelnemen aan de tafel om zelf was één van die lessen. Maar we zagen ook een heleboel mensen gebruik maken van een where clausule, die vrij traag resultaten veroorzaakt. We waren niet helemaal verrast door dit resultaat, want we zijn ons ervan bewust dat we niet de optimalisaties hebben gedaan op dat pad naar de snelle resultaten die we willen leveren. Maar het was een groot inzicht in hoe vaak het wordt gebruikt, en hoe mensen het gebruiken.
We zagen een aantal mensen gebruik maken van de groep by-overeenkomst clausule als goed, en vervolgens worden verrast dat het niet werkte. We waarschijnlijk mensen daarover moeten waarschuwen. Kortom, groep by-overeenkomst wordt automatisch afgeleid, zodat het niet nodig is. Maar omdat het helemaal niet is uitgevoerd, veroorzaakt een fout. Dus we zijn op zoek naar manieren om te behandelen dat.
Wij nemen al deze lessen ter harte nemen, en het maken van plannen naar het adres alles wat we zagen in de komende releases.
Conclusies
Het lijkt erop dat de overgrote meerderheid van de mensen die de demo geprobeerd zeer onder de indruk waren met het. De snelheid is werkelijk adembenemend.
Hier zijn slechts enkele van de opmerkingen die we kregen in de thread:
Ik misbruikt LEFT JOIN om een query die 224.964.999.650.251 rijen produceert te creëren. Alleen 3.68ms uitvoeringstermijn, nu dat is indrukwekkend!
Erg cool. Major props voor het aanbrengen van deze die er zijn en het accepteren van willekeurige queries.
Zeer indrukwekkend, ik denk dat het bouwen van je eigen (performant)-database vanaf nul is een van de meest indrukwekkende software engineering prestaties.
Erg cool en indrukwekkend !! Is vol PostreSQL draad compatibiliteit over het stappenplan? I like postgres compatibiliteit :)
(Ja, full PostgreSQL Wire Protocol is over het stappenplan!)
Mind blazen, nog niet wist over questDB. De knop terug lijkt gebroken op chroom mobile
Ja, de demo deed breken op de knop Terug in uw browser. Er is een echte reden voor, maar het is waar, voor nu. We zijn zeker aanpakken die men meteen.
Probeer het zelf
Wil je het zelf uit te proberen? Je hebt gelezen dit ver, je echt moet! moethttp://try.questdb.io:9000/ om het eens proberen.
We zouden je heel graag aan ons aan te sluiten op onze Community Slack Channel, geef ons een [Star on GitHub] (https://github.com/ questdb / questdb) en Download en probeer het zelf!
 Dutch
Dutch English
English Deutsche
Deutsche Español
Español Français
Français