



David G. Simmons
March 22, 2019
Het gebruik van Cross-Measurement wiskunde in InfluxDB Flux
Ik heb de uitgaven veel tijd de laatste tijd met de 2.0 Alpha releases en ik ben hier om u te vertellen: een aantal van de nieuwe dingen te komen zijn echt, echt cool! Speciaal voor ivd. Degene die ik heb de laatste tijd het gebruik is de mogelijkheid om wiskunde te doen over metingen, dat is echt een game-changer voor ivd data in InfluxDB geweest.
Laten we eens kijken is de reden waarom hier voor een minuut bij. Zoals u waarschijnlijk weet, heb ik het bouwen van een bos van ivd sensoren die stroom gegevens naar verschillende gevallen van InfluxDB. Een van de belangrijkste sensors ik een SenseAir K30 CO2 sensor. Het is een fabelachtig nauwkeurige sensor, maar het is niet goedkoop. Ik gebruik het voor een jaar of zo en het is uiterst betrouwbaar en nauwkeurig, maar ik vroeg me af hoe de temperatuur en de druk kan invloed hebben op de CO2-metingen. Wat ik vond was, natuurlijk, deze dingen in feite uit.
Ik las op het op hier, maar in wezen de en atmosferische druk invloed op de hoeveelheid gas in de meetkamer, niet de concentratie, zodat men moet compenseren. Het is een vrij eenvoudige berekening te maken met behulp van enkele referentiewaarden als absolute nulpunt en de druk op zeeniveau.
We zullen gebruik maken van de ideale gaswet formule:
ppm CO2 corrected = ppm CO2 measured * ((Temp measured * Pressure Reference ) / (Pressure measured * Temp Reference))
Super goed. Gemakkelijk! Bijna. Ik heb een temperatuur- / druksensor die opgeslagen waarden in een ‘omgeving’ Meting mijn InfluxDB geval. Mijn CO2 sensor slaat zijn lezingen in een “k30_reader” meting. Als u geen Flux, zie je al het probleem hier: Deze waarden leven in verschillende maten, dus ik kan ook niet deze berekening te doen of ik moet een behoorlijke hoeveelheid gymnastiek doen om de een of andere manier te herschrijven al deze waarden in een gemeenschappelijk eerste meting. Noch is echt een levensvatbare antwoord, is het?
Voer Flux en cross-meting wiskunde! Dus laten we lopen door hoe ik dit bereikt in Flux (met eenton hulp van collega devrel Anais, onder anderen). Een beetje opfriscursus over hoe Flux terugkeert waarden eerste. Laten we niet vergeten dat wanneer ik een vraag in te dienen Flux, krijg ik een tabel met waarden terug. Dit wordt belangrijk als we lopen door de manier waarop de Flux query wordt gebouwd, dus hou dat in gedachten.
Tref = 298.15
Pref = 1013.25
Tmeas = from(bucket: "telegraf")
|> range(start: v.timeRangeStart)
|> filter(fn: (r) => r._measurement == "environment" and (r._field == "temp_c"))
|> fill(column: "_value", usePrevious: true)
|> aggregateWindow(every: 30s, fn: mean)
|> keep(columns: ["_value", "_time"])
Eerste Ik heb mijn referentie temperatuur en druk waarden gedefinieerd. De referentietemperatuur is gewoonlijk 25 ° C, omgezet in Kelvin, en de referentiedruk is zeespiegel. Ik dan querywaarden van de gemeten temperatuurwaarden en opslaan in een lijst genoemd “Tmeas. Als ik opleveren () op deze tabel, zal ik mijn temperatuur waarden zien:
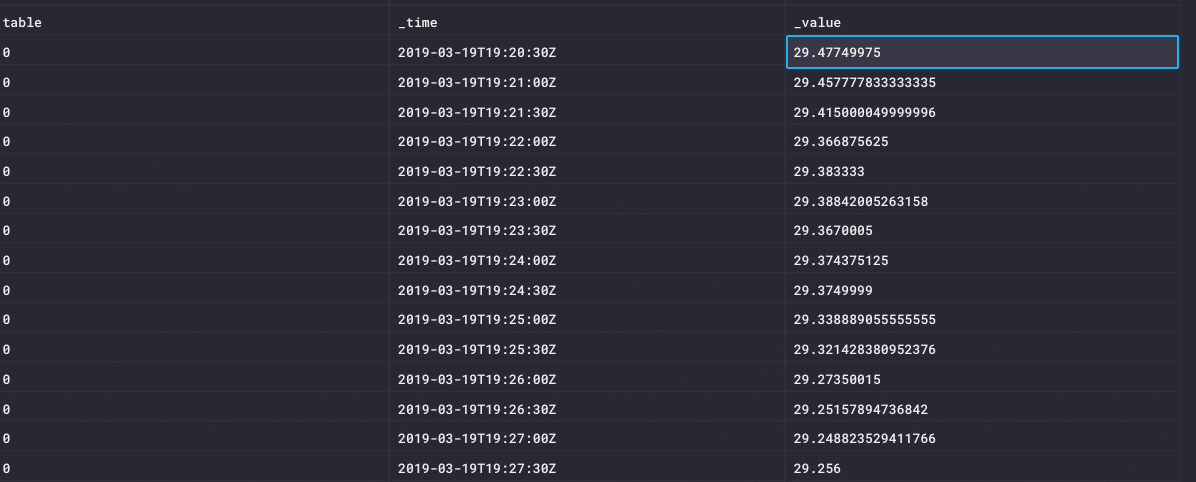
Ik herhaal dit voor de CO2 en Pressure waarden:
CO2meas = from(bucket: "telegraf")
|> range(start: v.timeRangeStart)
|> filter(fn: (r) => r._measurement == "k30_reader" and (r._field == "co2"))
|> fill(column: "_value", usePrevious: true)
|> aggregateWindow(every: 30s, fn: mean)
|> keep(columns: ["_value", "_time"])
Pmeas = from(bucket: "telegraf")
|> range(start: v.timeRangeStart)
|> filter(fn: (r) => r._measurement == "environment" and (r._field == "pressure"))
|> fill(column: "_value", usePrevious: true)
|> aggregateWindow(every: 30s, fn: mean)
|> keep(columns: ["_value", "_time"])
Super goed! Ik heb nu 3 tafels met alle waarden die ik nodig heb om mijn berekeningen uit te voeren. Alles wat ik nu moet doen is trekken ze allemaal samen, en ik zal dat doen door middel van een reeks van join () statements:
first_join = join(tables: {CO2meas: CO2meas, Tmeas: Tmeas}, on: ["_time"])
|> fill(column: "_value_CO2meas", usePrevious: true)
|>fill(column: "_value_CO2meas", value: 400.00)
|> fill(column: "_value_Tmeas",usePrevious: true)
|>fill(column: "_value_Tmeas", value: 20.0)
Deze eerste ‘join () `krijgt me een tabel met de CO2 en temperatuur waarden bevat, dus ik ben deel weg daar.
second_join = join(tables: {first_join: first_join, Pmeas: Pmeas}, on: ["_time"])
|>fill(column: "_value", usePrevious: true)
|>fill(column: "_value", value: 1013.25)
|>map(fn: (r) => ({_time: r._time, _Pmeas: r._value, _CO2meas:r._value_CO2meas, _Tmeas:r._value_Tmeas}))
Deze tweede join () krijgt me een tabel met alle gemeten waarden in het! Je zou denken dat ik zou worden gedaan, maar met het oog op de definitieve berekening te doen, want ik ben Deelnemen aan time, moet ik een finale tafel waar ik in de referentiewaarden te vullen voor elke rij in de tabel op te bouwen.
final = second_join
|>map(fn: (r) => ({Pmeas: r._Pmeas, CO2meas:r._CO2meas, Tmeas:r._Tmeas, Pref: Pref, Tref: Tref, _time: r._time,}))
|> keep(columns: ["_time", "CO2meas", "Pmeas", "Tmeas", "Pref", "Tref"])
Dus nu kan ik een finale tafel te maken en het berekenen van de gecompenseerde CO2-waarde, voor elke rij (tijd).
CO2corr = final
|> map(fn: (r) => ({"_time": r._time, "CO2-Measured": r.CO2meas, "CO2-Adjusted": r.CO2meas * (((r.Tmeas + 273.15) * r.Pref) / (r.Pmeas * r.Tref))}))
|> yield()
Aangezien dit mijn laatste tafel, ik noem opbrengst () aan het einde, zodat de waarden krijgt weergegeven.
En nu heb ik een grafiek die laat zien de rauwe, gemeten CO2-waarde en de gecompenseerde CO2-waarde! Alle gedaan on-the-fly met behulp van cross-meting math Flux’s!
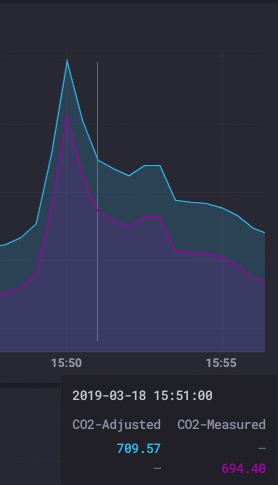
 Dutch
Dutch English
English Deutsche
Deutsche Español
Español Français
Français