
David G. Simmons
donderdag 16 april 2020
Dit spul is SNEL!
Ik heb veel van projecten met behulp van InfluxDB de afgelopen jaren gedaan (nou ja, ik maakte er na alle) dus misschien heb ik een beetje een bias, of een blinde-spot. Als u (https://twitter.com/intent/follow?screen_name=davidgsIoT) [me volgen] op Twitter, dan kunt u mij hebben zien na een aantal korte video’s van een project waaraan ik werkte voor het visualiseren COVID-19 data op een kaart.
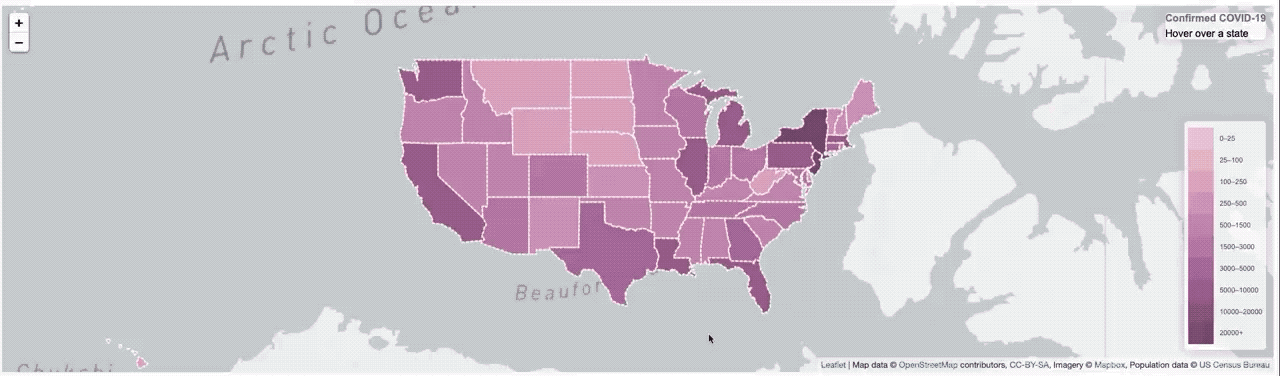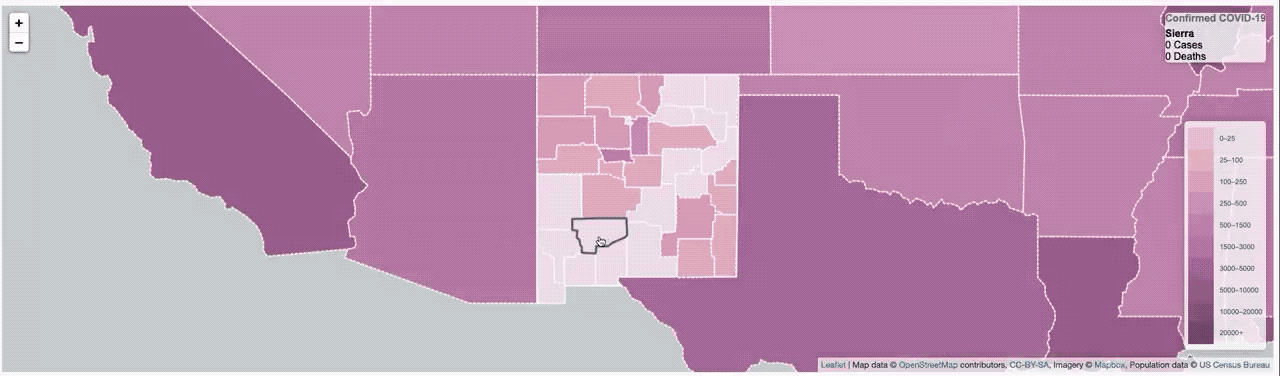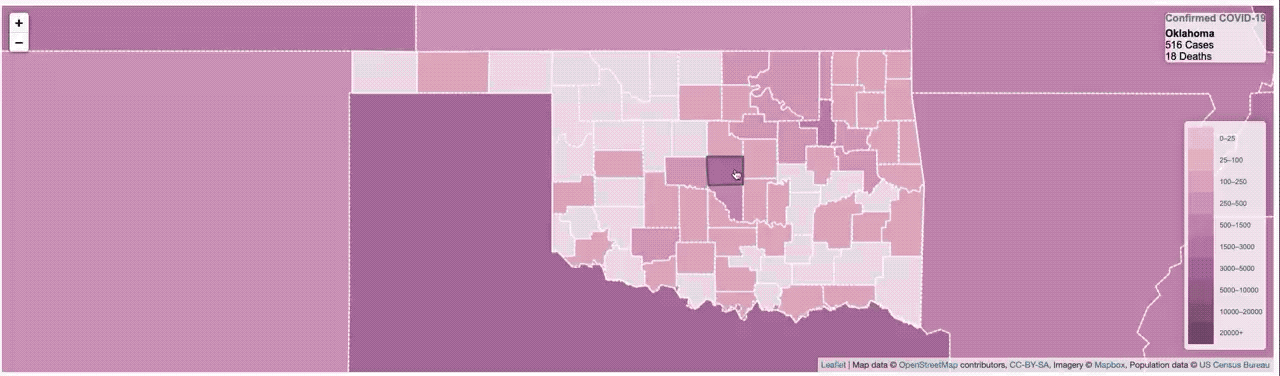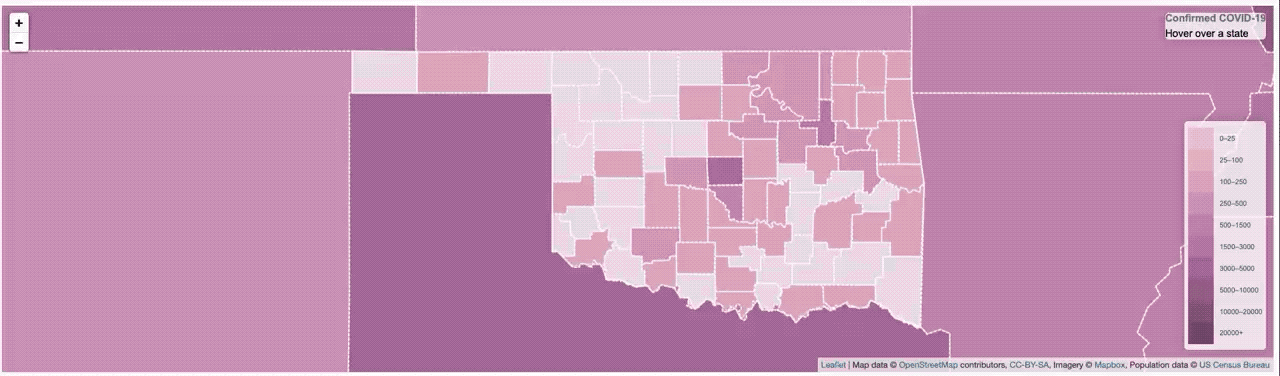 It worked, but it was pretty slow. So much so that I had to put a ’loading’ overlay on it so you knew it was still actually doing something while it was querying the data from the database. I actually sort of thought it was pretty fast, until I started trying to load data from all of Asia, or all of Europe, where that was a lot of data and the query got complicated.
It worked, but it was pretty slow. So much so that I had to put a ’loading’ overlay on it so you knew it was still actually doing something while it was querying the data from the database. I actually sort of thought it was pretty fast, until I started trying to load data from all of Asia, or all of Europe, where that was a lot of data and the query got complicated.
Maar, omdat ik niet meer werk bij InfluxData heb ik besloten om tak uit een beetje en probeer een aantal andere oplossingen. Ik bedoel, wat is het kwaad, toch? Ik vond dit kleine startup bezig met een SQL gebaseerde Time Series database genaamd [QuestDB] (https://questdb.io/?ref=davidgsiot) dus ik dacht dat ik het eens proberen. Echt klein (in feite integreerbare) en alle geschreven in Java (hey, ik vroeger deed Java! Gestart in 1995 in feite!), Dus wat de hel.
Eerlijk gezegd, ik ben verbijsterd. De prestaties van dit ding is mind-blowing. Kijk maar naar dit:
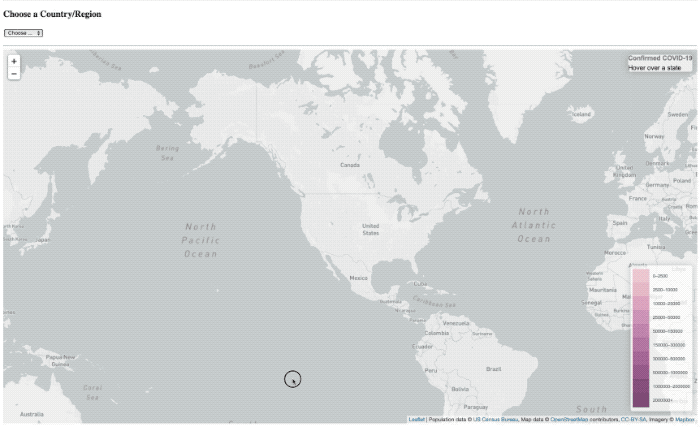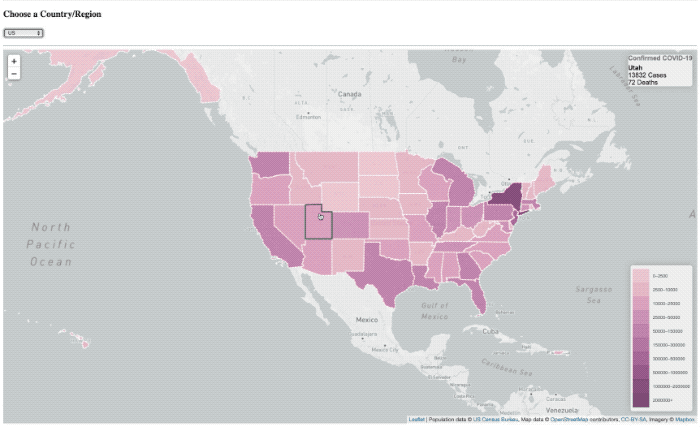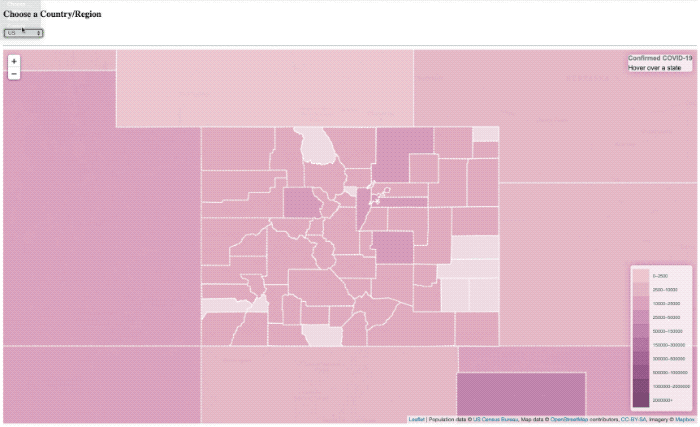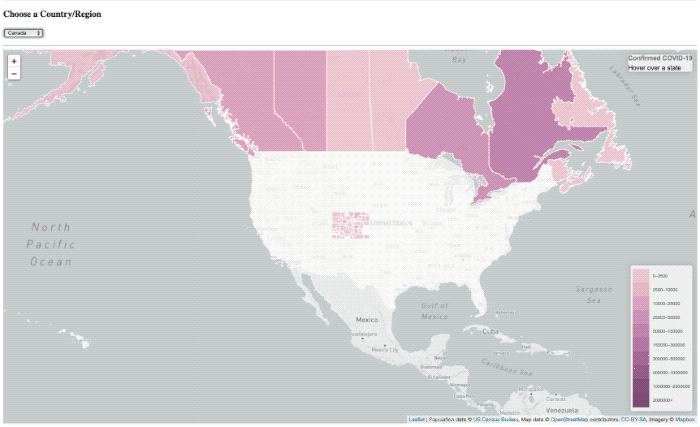
De ’laden’ overlay is er nog steeds, het is gewoon in principe niet de tijd om meer te laten zien hebben.
Daarnaast is de query-taal is … SQL. Hell, zelfs *** I *** weet SQL! Ik moet het stof een beetje af, want het is al jaren geleden dat ik schreef er zijn, maar het is net als fietsen, meestal.
Je bent waarschijnlijk gaan om te vragen, omdat ik van het al eerder maakte zo’n big deal, “ja, maar hoe lang duurde het om het op te zetten?” Ik zal je vertellen: 30 seconden. Ik downloadde het en liep de questdb.sh start script en … het werd opgericht. Natuurlijk, het had geen gegevens, dus ik moest het allemaal in te laden. Ok, dus hoe lang heeft dat duren? En hoe moeilijk was het? Nou, ummm …
Ik veranderde mijn Go-programma dat eerder had omgetoverd al de John Hopkins COVID-19 gegevens uit hun CSV-bestanden naar Influx Line Protocol bestanden, dus ik een paar minuten doorgebracht te veranderen dat, zodat het vermogen alles in één geïntegreerde , genormaliseerde CSV-bestand (JHU verandert de indeling van hun csv-bestanden heel vaak, dus ik moet blijven aanpassen). Zodra ik dat had, ik heb net slepen en liet hem in de QuestDB interface:
In het geval dat je het gemist, was het 77.000 rijen in 0,2 seconden ingevoerd.

Oh, en toen klikte ik op het pictogram ‘view’ en … 77.000 rijen lezen in 0,016 seconden. En dat aantal is niet een typo. nulpunt-nul-1-6 seconden. Toegegeven, de rijen zijn niet zo groot, maar toch, dat is onheilig snel.
Dus nu heb ik een nieuw speeltje om mee te spelen, en ik zal zien wat ik kan doen, dat is leuk, en waarschijnlijk meer ivd verwant.
Blijf kijken.