
David G. Simmons
vrijdag 13 maart 2020
Snack Tracking met de nieuwe InfluxDB Arduino Library
een nieuwe bibliotheek
Velen van jullie Arduino liefhebbers zijn waarschijnlijk op de hoogte van de bestaande InfluxDB bibliotheek die door Tobias Schürg voor vele jaren werd gehandhaafd. Hoeden zijn af voor hem voor het verstrekken van deze bibliotheek en het onderhoud van het voor zo lang.
Met de komst van InfluxDB 2.0, was het tijd om de bibliotheek te werken. Sommigen van u kunnen herinneren dat ik heb een snelle update van de InfluxDB 2,0 OSS ondersteunen een paar maanden geleden, en dat werkte goed, maar InfluxData heeft gewerkt in de richting van een set van consistente, InfluxData onderhouden set van client libraries. Ze hebben gewerkt met Tobias in de afgelopen paar maanden de tijd om zijn bibliotheek updaten met onze nieuwste veranderingen, en word een handhaver van die bibliotheek. Ik ben blij om te zeggen dat al dat werk heeft zijn vruchten afgeworpen, en de nieuwe InfluxDB Arduino Library wordt officieel uitgebracht, en is ook onderdeel van de [docs] (https://v2.docs.influxdata.com/v2.0 / referentie / api / client-libraries /).
een aantal belangrijke Toevoegingen
Deze nieuwe versie van de bibliotheek, terwijl achterwaarts compatibel met de oudere versie (meestal) heeft een aantal echt grote veranderingen voor de 2.0 versie van InfluxDB terwijl de ondersteuning van de 1.x lijn.
Batch schrijven is nog steeds ondersteund, maar het is veel meer naadloos en efficiënt. Ik heb gewerkt met het een beetje, en er is niet langer een noodzaak om een batch teller te houden en met de hand schrijven de batch. Het is allemaal voor u afgehandeld. Misschien het belangrijkst is de mogelijkheid om de HTTP-verbinding in leven, die de overhead van instantiëren de verbinding en scheuren malen ingetrapt bespaart te houden. Zolang je betrouwbaar WiFi, dat is.
Er is nu ook ondersteuning voor de behandeling van database back druk. Als je schrijft niet door te gaan, zal de bibliotheek de schrijft dat lukte niet en probeer ze opnieuw in de cache, en de grootte van de tegendruk cache kan worden geconfigureerd.
Er is nu een eenvoudige manier om tijd stempels en tijdsynchronisatie behandelen in de bibliotheek zelf. U kunt de tijd nauwkeurig in te stellen en de bibliotheek verzorgt automatisch de tijd stempelen voor u.
Er is nog veel meer, ik ben er zeker van (met inbegrip van de behandeling van SSL-verbindingen), die ik nog niet heb gekregen om mee te werken, maar ik weet zeker dat ik een kans krijgt binnenkort!
Een snack Tracker
Gezien het feit dat deze nieuwe bibliotheek kwam net uit, ik dacht dat ik zou het ten minste een keer meteen kon beproeven. Om dit te doen, wilde ik eenlot van gegevens te schrijven om er doorheen te zien hoe het opgehouden. Om dat te doen, ik ging naar buiten en een beetje DYI digitale weegschaal die een HX711 gebruikt om interface naar de Load Cell gekocht. toen ik verslaafd dat een WEMOS D1 Mini (natuurlijk, want ik heb zo veel van hen rond), en ik was klaar om te gaan! Ik bedraad het op:
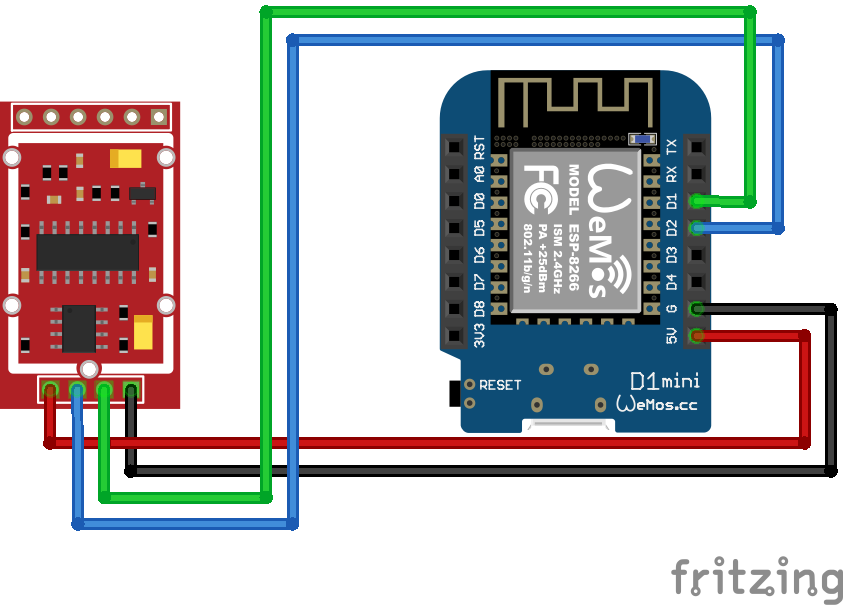
De Arduino Bibliotheek voor de HX711 kwam met een voorbeeld programma voor het kalibreren van de schalen, en ik soort van de te verwachten ze te hoeven kalibreren, dus ik een set van kalibratiegewichten kocht toen ik de schaal gekocht. De Calibration programma slaat zelfs de kalibratie gegevens naar de EEPROM voor u, zodat het altijd is gekalibreerd. Het lijkt alsof het is juist tot op ongeveer 0,05 gram, voor het grootste deel.
Code Time
Nu dat het toestel werd gebouwd, was het tijd om een beetje van code te schrijven om al deze gegevens te versturen naar InfluxDB! Gelukkig is de HX711 bibliotheek kwam ook met een monster programma voor slechts spuwen uit onbewerkte gegevens van het apparaat, dus alles wat ik moest doen was te modificeren dat ooit zo iets om mijn gegevens te InfluxDB sturen.
// InfluxDB 2 server url, e.g. http://192.168.1.48:9999 (Use: InfluxDB UI -> Load Data -> Client Libraries)
#define INFLUXDB_URL "influxdb-url"
// InfluxDB 2 server or cloud API authentication token (Use: InfluxDB UI -> Load Data -> Tokens -> <select token>)
#define INFLUXDB_TOKEN "token"
// InfluxDB 2 organization name or id (Use: InfluxDB UI -> Settings -> Profile -> <name under tile> )
#define INFLUXDB_ORG "org"
// InfluxDB 2 bucket name (Use: InfluxDB UI -> Load Data -> Buckets)
#define INFLUXDB_BUCKET "bucket"
InfluxDBClient client(INFLUXDB_URL, INFLUXDB_ORG, INFLUXDB_BUCKET, INFLUXDB_TOKEN);
HX711_ADC LoadCell(D1, D2);
Je zal natuurlijk, moet je eigen URL, symbolisch, etc. definieer ik zet de load cell op D1 en D2, dus dat is hier gedefinieerd ook.
Vervolgens heb ik het volgende toegevoegd aan het einde van de setup () routine:
// Synchronize UTC time with NTP servers
// Accurate time is necessary for certificate validaton and writing in batches
configTime(0, 0, "pool.ntp.org", "time.nis.gov");
// Set timezone
setenv("TZ", "EST5EDT", 1;
influx.setWriteOptions(WritePrecision::MS, 3, 60, true);
Dat stelt de tijd synchronisatie, en stelt mijn tijd precisie milliseconden, stelt de partij uit, de grootte buffer (wat in mijn geval I bij de partij uit 3x), de flush interval (ik zorg ervoor dat het een flush gebeurt ten minste elke 60 seconden) en ik de http-keepalive om waar dus ik dezelfde verbinding elke keer kunt gebruiken.
Dat was alles wat de setup ik moest doen!
Vervolgens moet ik de gegevens te schrijven. En hier is het ding, de HX711 voorbeeld programma leest de schaal elke 250 ms
float weight = 0.00;
void loop() {
//update() should be called at least as often as HX711 sample rate; >10Hz@10SPS, >80Hz@80SPS
//use of delay in sketch will reduce effective sample rate (be carefull with use of delay() in the loop)]{style="color: #999dab;"}
LoadCell.update();
//get smoothed value from data set
if(millis() > t + 250) {
float i = LoadCell.getData();
weight = i;
t = millis();
}
writeData(weight);
...
}
void writeData(float weight) {
Point dPoint();
dPoint.addTag("device", "ESP8266");
dPoint.addTag("sensor", SENSOR_ID);
dPoint.addField("weight", weight);
Serial.print("Weight: ");
Serial.println(weight);
if(!influx.writePoint(dPoint)) {
Serial.print("InfluxDB write failed: ");
Serial.println(influx.getLastErrorMessage());
}
In de bovenstaande code Ik ben het schrijven van een nieuwe data point, met labels, enz., Elke 250 ms. U zult merken dat ik blijf het schrijven van de data punten. Maar op de achtergrond, de bibliotheek is de behandeling van het groeperen, caching, tegendruk, retries, enz. Ik gewoon aan het vrolijk write datapunten zonder na te denken over hen meer.
Kleverige beren
Als je me weten helemaal niet, zult u ook weten dat ik een soort vaniets voor gummy bears. Dus besloot ik om dit ding te testen uitgevoerd door het laden van het met een kom van gummy beren, en het kijken naar de gegevens als ik hen aten. Lo en zie, het werkt!
Je kunt zien dat wanneer ik mijn hand steken in de kom om wat te krijgen, het gewicht omhoog gaat gewoon een beetje, dan daalt. Natuurlijk moest ik een Gummy Bear Dashboard te maken:
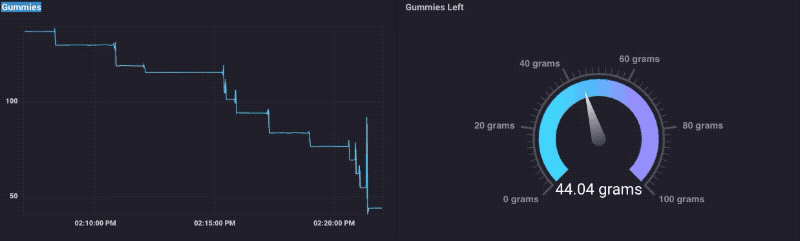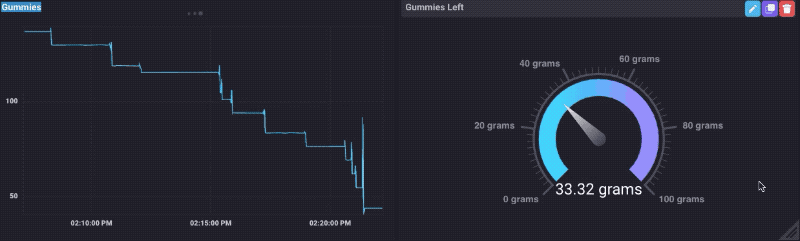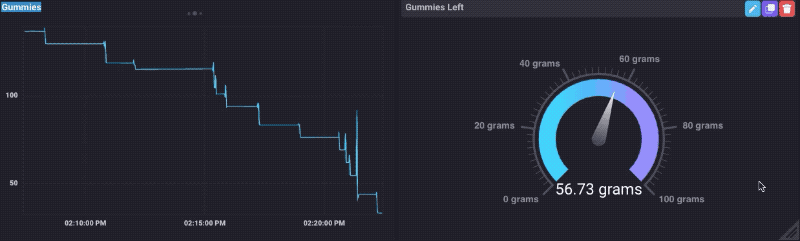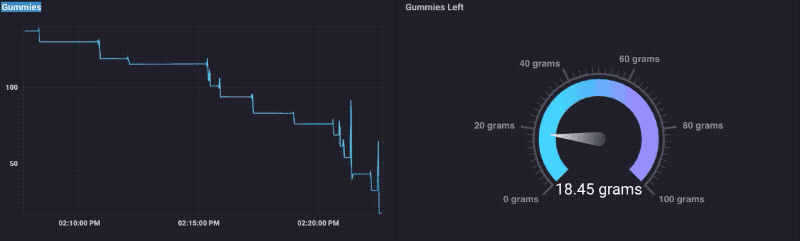
Dat was echt een soort van plezier, totdat ik liep uit Gummy Bears.
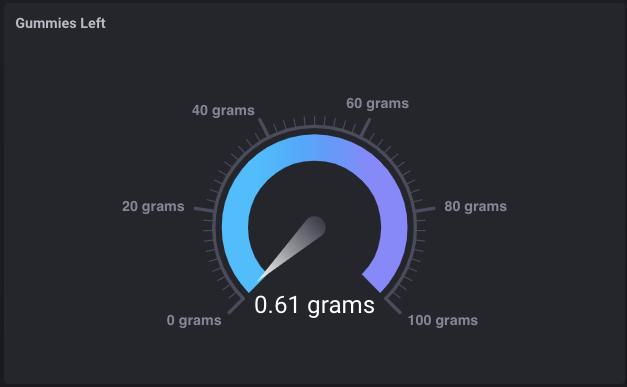
Tot nu toe deze zaak loopt al een paar uur en ik heb nog geen enkele foutmelding of hik van het apparaat zelf te zien, zodat het lijkt alsof het groeperen, cacheing, enz. Is allemaal perfect werkt.