
David G. Simmons
donderdag 5 december 2019
Ivd gegevens uit andere bronnen MySQL
Als u een ivd oplossing hebben geïmplementeerd, heb je moest beslissen waar en hoe, om al uw gegevens op te slaan. Althans vanuit mijn perspectief, de beste en gemakkelijkste plaats om de sensor data op te slaan is natuurlijk, InfluxDB. Mijn zeggen dat kan niet komen als een verrassing voor je. Maar hoe zit hetandere gegevens die u nodig hebt om op te slaan? De gegevensOver de sensoren? Dingen zoals de fabrikant sensor, de datum waarop het is geplaatst in dienst, de klant-ID, wat voor soort platform waarop het draait. Je weet wel, alle sensor metadata het.
Een oplossing is natuurlijk om gewoon al die dingen als tags toe te voegen aan uw sensor data in InfluxDB en gaan over je dag. Maar wil jeecht willen al uw sensor gegevens met elke datawaarde op te slaan? Veel dingen lijkt misschien een goed idee op het moment, maar daarna snel overgaan in een vreselijk idee wanneer de werkelijkheid hits. Aangezien de meeste van deze metadata niet vaak veranderen, en kan ook worden geassocieerd met informatie over klanten, de beste plek, want het is zeer waarschijnlijk in een traditionele RDBMS. Waarschijnlijk heb je almoet een RDBMS met de gegevens van de klant in het, dus waarom niet gewoon doorgaan met leverage die investering? Zoals ik al herhaaldelijk heb gezegd, dit is niet de beste plaats voor uw sensor data. Dus nu heb je je ivd gegevens kregen in twee verschillende databases. Hoe ga je er toegang toe te fuseren tot een plek waar je kunt het allemaal zien?
Flux is het antwoord
Zeg me dat je zag dat aankomen. Je moest hebben gezien dat komen. Ok, om eerlijk te zijn, kan het nodig zijn, want immers, hoe ga je om uw SQL-gebaseerde data te krijgen via Flux? Dat is het mooie van Flux: het is uitbreidbaar! We hebben nu dus een extensie die u toelaat om gegevens te lezen van zowel MySQL, MariaDB of Postgres via Flux. Toen ik hoorde dat dit SQL connector klaar was om te gaan, ik had net het te proberen. Ik zal je laten zien wat ik gebouwd, en hoe.
Bouw een klantendatabase
Het eerste wat je moet doen is het bouwen van een MySQL database met een aantal Customer Information. Ik heb een nieuw database genaamd IoTMeta waarin ik een tafel met enkele sensor metadata. Ik heb ook een andere tabel met klantinformatie over de sensoren.

Vrij eenvoudig tafels, echt waar. De Sensor_ID veld Ik gevuld met gegevens die overeenkomen met de Sensor_id tag in mijn InfluxDB instantie. Ik wed dat je kunt zien waar ik ga met dit al. Ik voegde een bos van gegevens:

Dus nu mijn sensor metadata database wat informatie over elke sensor die ik hier hardlopen, evenals een aantal ‘customer data’ over wie de eigenaar van de sensoren. Nu is het tijd om dit alles te trekken in iets nuttigs.
Query de gegevens Flux
Ten eerste, ik bouwde een query in Flux om een aantal van mijn sensor data te krijgen, maar ik was niet echt geïnteresseerd in de sensor data zelf. Ik was op zoek naar een identificerend Tag waarde: Sensor_id. Deze query ziet er een beetje vreemd, maar het zal zinvol op het einde, dat beloof ik.
temperature = from(bucket: "telegraf")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r._measurement == "temperature" and (r._field == "temp_c"))
|> last()
|> map(fn: (r) => {
return { query: r.Sensor_id }
})
|> tableFind(fn: (key) => true) |> getRecord(idx: 0)
Het geeft een tabel van een rij, en dan trekt de Sensor_id tag, en dat is waar je waarschijnlijk je zegt“Whaaaat?” Denk eraan: Flux keert alles in tabellen. Wat ik nodig heb is in wezen een scalaire waarde te halen uit die tabel. In dit geval, het is een string waarde voor de Tag in kwestie. Dat is hoe je dat doet.
Vervolgens ga ik naar de gebruikersnaam en het wachtwoord voor mijn MySQL database, die gemakkelijk in de InfluxDB Secrets Store wordt opgeslagen.
uname = secrets.get(key: "SQL_USER")
pass = secrets.get(key: "SQL_PASSW")
Wacht, hoe ben ik deze waarden in dit Secrets winkel eigenlijk? Goed, laten we een back-up van een minuut.
curl -XPATCH http://localhost:9999/api/v2/orgs/<org-id>/secrets -H 'Authorization: Token <token>' -H 'Content-type: application/json' --data '{ "SQL_USER": “<username>" }'
Een ding op te merken is dat je de <org-id> Uit uw URL. Het is niet de werkelijke naam van uw organisatie in InfluxDB. Dan doe je hetzelfde voor de ‘SQL_PASSW` geheim. Je kunt ze alles wat je wilt noemen, echt waar. Nu hoeft u niet om uw gebruikersnaam en / of wachtwoord in uw zoekopdracht zet in platte tekst.
Vervolgens ga ik dat allemaal gebruiken om mijn SQL-query op te bouwen:
sq = sql.from(
driverName: "mysql",
dataSourceName: "${uname}:${pass}@tcp(localhost:3306)/IoTMeta",
query: "SELECT * FROM Sensor_data, Customer_Data WHERE Sensor_data.Sensor_ID = ${"\""+temperature.query+"\" AND Sensor_data.measurement = \"temperature\" AND Sensor_data.CustomerID = Customer_Data.Customer_ID"}" //"SELECT * FROM Sensor_data WHERE Sensor_ID = ${"\""+temperature.query+"\" AND measurement = \"temperature\""}" //q // humidity.query //"SELECT * FROM Sensor_Data WHERE Sensor_ID = \"THPL001\""// humidity.query
)
U zult zien dat ik ben met behulp van de waarde van mijn eerste Flux query in de SQL-query. Koel! U kunt ook merken dat ik het uitvoeren van een join in dat SQL-query, zodat ik gegevens kan krijgen vanbeide tabellen in de database. Hoe cool is dat? Vervolgens zal ik de resulterende tabel opmaken om alleen de kolommen Ik wil weergave te hebben:
fin = sq
|> map(fn: (r) => ({Sensor_id: r.Sensor_ID, Owner: r._Sensor_owner, Manufacturer: r.Sensor_mfg, MCU_Class: r.MCU_class, MCU_Vendor: r.MCU_vendor, Customer: r.Customer, Address: r.Address, Phone: r.phone}))
Ik heb nu een tabel die alle bevat de metadata over mijn sensor, evenals alle van de klant contact gegevens daarover sensor. Het is tijd voor wat magie:
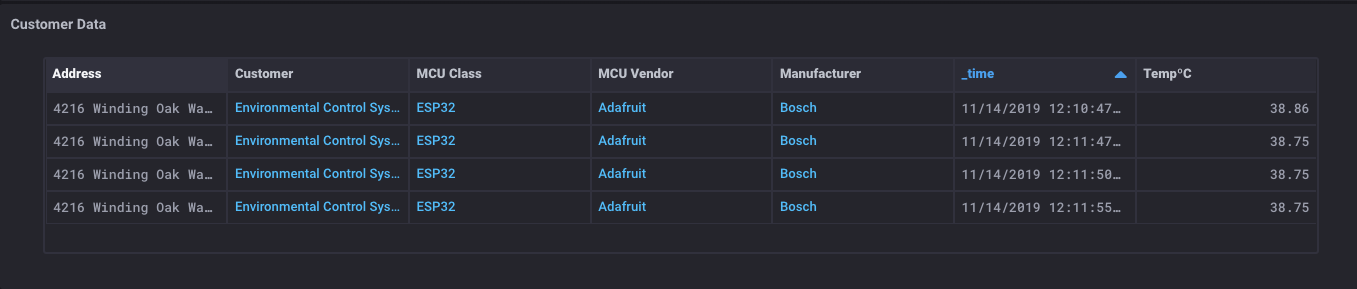
Wat voor tovenarij is dit? Ik heb een tabel die alle metadata over de sensor, wat de klant data, en de sensorwaarden heeft ook? Yep. Ik doe. En hier is het echt magisch ding: Omdat u gegevens kunt krijgen van zowel SQL databasesen InfluxDB emmers, dan kunt u ook samen te voegen die gegevens in één tabel.
Hier is hoe ik dat deed:
temp = from(bucket: "telegraf")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r._measurement == "temperature" and (r._field == "temp_c"))
Krijgt me een tabel van de sensor data. Ik heb al een tabel van de metadata van SQL, dus …
j1 = join(tables: {temp: temp, fin: fin}, on: ["Sensor_id"] )
|> map(fn: (r) => ({_value: r._value, _time: r._time, Owner: r.Owner, Manufacturer: r.Manufacturer, MCU_Class: r.MCU_Class, MCU_Vendor: r.MCU_Vendor, Customer: r.Customer, Address: r.Address, Phone: r.phone}))
|> yield()
Ik sluit me gewoon die twee tafels op een gemeenschappelijk element (het Sensor_id veld) en ik heb een tabel die alles op een plek heeft!
Er zijn een aantal manieren dat u deze mogelijkheid om gegevens samenvoegen van verschillende bronnen kan gebruiken. Ik zou graag horen hoe je zoiets als dit zou implementeren om beter te begrijpen uw sensor implementaties.
Ik heb dit alles gedaan met behulp van de Alpha18 build van InfluxDB 2.0, dat is wat ik run - eigenlijk op maat te bouwen mijn versie van de master, want ik heb een aantal toevoegingen aan Flux die ik gebruik, maar dat is een heel ander bericht. Voor dit spul, de Alpha builds van OSS InfluxDB 2.0 werken prima. Je moet absoluut eens te proberen!