
David G. Simmons
lundi 18 décembre 2017
« Construire IdO Gateway Device pour Alerting local et données sous-échantillonnage »
Il y a toutes sortes de façons d’architecte votre IdO de déploiement, et ce qui est bon pour une entreprise ne sera pas nécessairement bon pour l’autre. En fonction de la taille et de la complexité de votre projet IdO, il peut y avoir, bien sûr, beaucoup de composants. Une des architectures plus universelles consiste à déployer concentrateurs de capteurs ou dispositifs de passerelle pour collecter des données à partir d’un certain nombre de noeuds de capteurs et ensuite vers l’avant que les données relatives à un système de collecte de données en amont pour l’entreprise. Ces dispositifs de passerelle ou un concentrateur permettent généralement un dispositif de ZWave pour se connecter à Internet pour le téléchargement de données ou de pont entre les périphériques Bluetooth à une connexion Wi-Fi ou autre connexion réseau.
De plus, la plupart de ces dispositifs de passerelle ou un concentrateur ont tendance à être des passerelles « muets ». Ils ne font rien d’autre que des données vers l’avant sur un collecteur en amont. Mais si la passerelle IdO pourrait être un appareil intelligent? Que faire si vous pouvez faire des analyses locales et traitement des données sur le concentrateur ** avant ** envoyer les données sur? Ce ne serait pas utile!
Construire une passerelle
J’ai décidé de construire (un autre) dispositif IdO passerelle Smart ce matin. J’ai (sorte de) construit un avant sous la forme d’un ARTIK-520 en cours d’exécution InfluxDB. Mais un ARTIK-520 est pas la chose moins cher là-bas, et quand vous construisez des appareils IdO, parfois moins cher est meilleur. Pas toujours, mais quand vous construisez beaucoup, beaucoup de portes d’entrée, vous préférez ne pas casser la banque sur eux. Je creusais ma boîte) sous la forme d’un ARTIK-520 en cours d’exécution InfluxDB. Mais un ARTIK-520 est pas la chose moins cher là-bas, et quand vous construisez des appareils IdO, parfois moins cher est meilleur. Pas toujours, mais quand vous construisez beaucoup, beaucoup de portes d’entrée, vous préférez ne pas casser la banque sur eux. Je creusais ma boîte Pin-64 que je l’ai acheté il y a quelques années et se mettent au travail. Pourquoi Pine-64 et non Raspberry Pi? Eh bien, le pin-64 est d’environ 1/2 le coût. Oui, 1/2 le coût. Il est 15 $ au lieu de 35 $, donc il y a cela. Il a exactement le même ARM A53 quad-core processeur 1,2 GHz - le mien a 2 Go de mémoire, par rapport à 1 Go sur un RPI - et il a un GPU plus puissant, si vous êtes dans ce genre de chose. Il est également venu avec WiFi intégré, donc pas de dongle, et je me suis le ZWave carte optionnelle pour que je puisse parler à des appareils sous-GHz IdO.
L’une des belles choses au sujet de l’exécution de ces types de dispositifs tels que les passerelles IdO est que vous êtes seulement limité dans votre stockage par la taille de la carte microSD que vous utilisez. Je suis seulement en utilisant une carte de 16 Go, mais le pin-64 peut prendre jusqu’à une carte 256Go.
Que faut-il pour obtenir le TICK pile et en cours d’exécution sur un pin-64? Sans surprise, le temps Awesome ™ est vraiment court! Une fois que vous avez votre boîte Pine-64 et en cours d’exécution - Je suggère d’utiliser l’image Xenial comme il est l’image de pin-64 « officielle » et il est Ubuntu, il est donc très facile avec InfluxDB. Ne pas oublier de courir
apt-get upgrade
Dès que vous avez et en cours d’exécution pour vous assurer que votre avoir tout à jour.
Ensuite, ajoutez les dépôts Afflux à apt-get:
curl -sL https://repos.influxdata.com/influxdb.key | apt-key add -
source /etc/lsb-release
echo "deb https://repos.influxdata.com/${DISTRIB_ID,,} ${DISTRIB_CODENAME} stable" | tee -a /etc/apt/sources.list
Vous aurez probablement à courir ceux avec sudo, mais je triche et exécuter bash sudo ‘pour commencer et je suis prêt.
Ensuite, vous aurez besoin d’ajouter un paquet qui manque - et nécessaire - afin d’accéder aux dépôts InfluxData:
apt-get install apt-transport-https
Ensuite, il est juste une question de
apt-get install influxdb chronograf telegraf kapacitor
et vous êtes prêt à partir!
Test du dispositif de charge
J’ai décidé qu’il pourrait être une bonne idée de mettre une charge sur ce petit appareil juste pour voir ce qu’il était capable de gérer, donc je téléchargé « afflux stress » de GitHub et il a couru contre ce dispositif.
Using batch size of 10000 line(s)
Spreading writes across 100000 series
Throttling output to ~200000 points/sec
Using 20 concurrent writer(s)
Running until ~18446744073709551615 points sent or until ~2562047h47m16.854775807s has elapsed
Wow … c’est de 200.000 points par seconde! Cela devrait mettre un peu de stress grave sur mon petit pin-64! Et il se trouve qu’il a fait en quelque sorte:
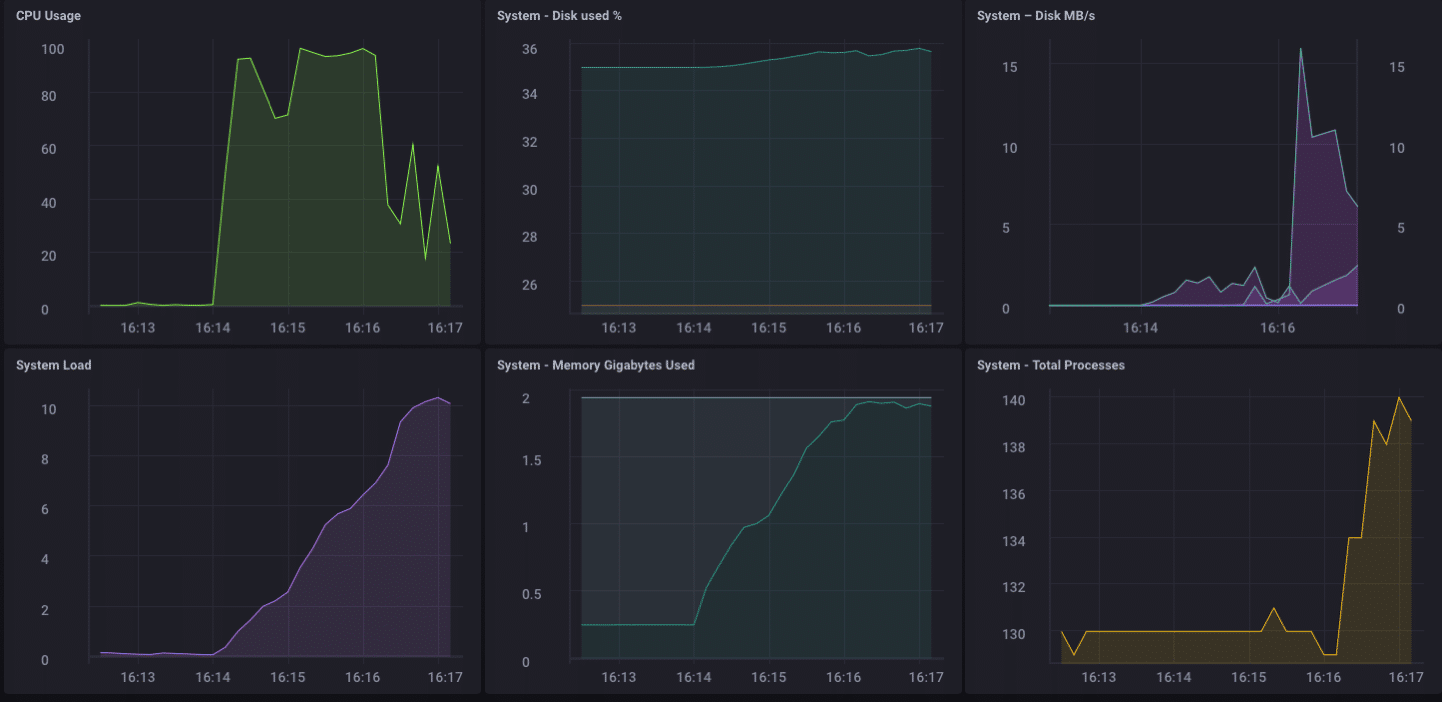
Comme vous pouvez le voir, assez rapidement surmonté la 2 Go de mémoire et le CPU arrimé à 100%. Mais en tant que dispositif de passerelle, il est peu probable, dans la vie réelle, de voir une telle charge. Je pense, en termes d’utilisation de la vie réelle comme une passerelle, je serais bien dans ma gamme si je percevais que de quelques dizaines à peut-être une centaine de capteurs.
Analytics local
Comme vous pouvez le voir sur le tableau de bord ci-dessus, je peux facilement faire des analyses locales sur le pin-64. Il dispose d’une interface intégrée HDMI, et un GPU complet, permettant ainsi l’accès local au tableau de bord pour la surveillance est mort simple. Mais comme je le disais plus tôt, il serait beaucoup plus utile si l’appareil pouvait faire plus que cela. Il est peu probable que, dans le monde réel, vous allez recueillir toutes vos données sur un périphérique de passerelle et de faire toutes vos analyses, etc. là. Ce n’est pas ce que les passerelles / hubs sont pour. * * Certaines analyses locales, d’alerte, etc. serait bon - déplacer une partie du traitement vers le bord quand vous pouvez - mais vous voulez toujours de transmettre des données en amont.
Downsampling les données
Il est assez facile à utiliser simplement un dispositif de passerelle pour transmettre ** tous ** vos données en amont, mais si vous avez affaire à des problèmes de connectivité réseau, et vous essayez d’économiser de l’argent ou la bande passante, ou les deux, vous allez vouloir de faire quelques données avant de sous-échantillonnage transférer vos données. Heureusement, cela est aussi très facile à faire! Un dispositif de passerelle qui peut faire des analyses locales, gérer une alerte locale, et peut également sous-échantillonner les données avant de les transmettre en amont est extrêmement utile dans IdO. Il est également assez simple à faire!
Tout d’abord, nous allons mettre en place notre dispositif de passerelle pour pouvoir transmettre des données en amont pour une autre instance de InfluxDB. Il y a plusieurs façons de le faire, mais étant donné que nous allons faire des données via le sous-échantillonnage Kapacitor, nous allons le faire via le fichier kapacitor.conf. Le fichier kapacitor.conf a déjà une section avec un [[influxdb]] entrée pour « localhost » donc nous avons juste besoin d’ajouter un nouveau [[influxdb]] section pour l’instance en amont:
[[influxdb]]
enabled = true
name = "mycluster"
default = false
urls = ["http://192.168.1.121:8086"]
username = ""
password = ""
ssl-ca = ""
ssl-cert = ""
ssl-key = ""
insecure-skip-verify = false
timeout = "0s"
disable-subscriptions = false
subscription-protocol = "http"
subscription-mode = "cluster"
kapacitor-hostname = ""
http-port = 0
udp-bind = ""
udp-buffer = 1000
udp-read-buffer = 0
startup-timeout = "5m0s"
subscriptions-sync-interval = "1m0s"
[influxdb.excluded-subscriptions]
_kapacitor = ["autogen"]
Cela permet de résoudre une partie du problème. Maintenant, nous devons effectivement Downsample les données, et envoyez-le. Depuis que je suis en utilisant Chronograf v1.3.10, j’ai un éditeur intégré TICKscript, donc je vais aller à l’onglet « Alerting » dans Chronograf, et créer un nouveau script TICK, et sélectionnez la base de données telegraf.autoget comme ma source :
Je ne suis pas la collecte des données du capteur fait sur cet appareil, donc je vais utiliser l’utilisation du processeur comme mes données, et je downsample dans mon TICKScript. J’ai écrit un TICKScript très basique pour downsample mes données CPU et le transmettre en amont:
stream
|from()
.database('telegraf')
.measurement('cpu')
.groupBy(*)
|where(lambda: isPresent("usage_system"))
|window()
.period(1m)
.every(1m)
.align()
|mean('usage_system')
.as('mean_usage_system')
|influxDBOut()
.cluster('mycluster')
.create()
.database('downsample')
.retentionPolicy('autogen')
.measurement('mean_cpu_idle')
.precision('s')
Ce script prend simplement le champ usage_system de la mesure du CPU chaque minute, calcule la moyenne, et écrit alors qu’en amont de la valeur à mon instance amont InfluxDB. Sur le dispositif de passerelle, les données du processeur ressemble à ceci:
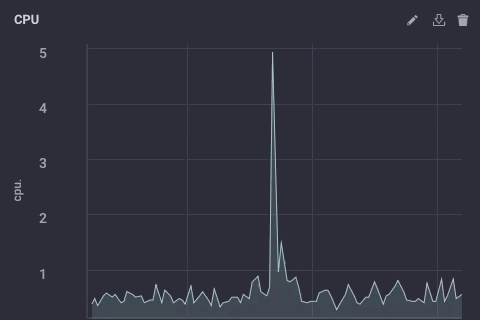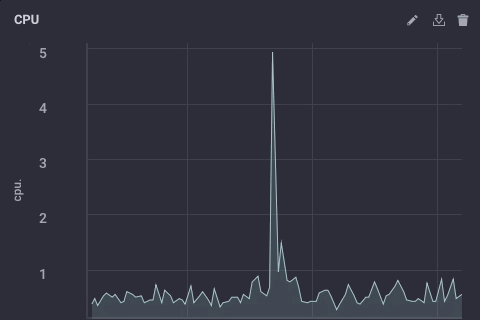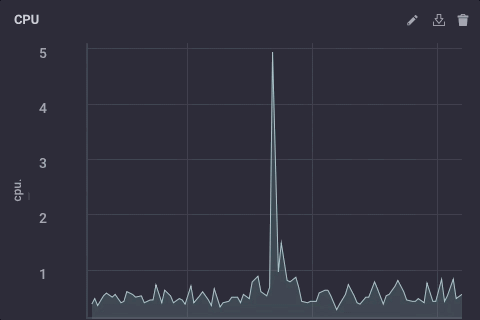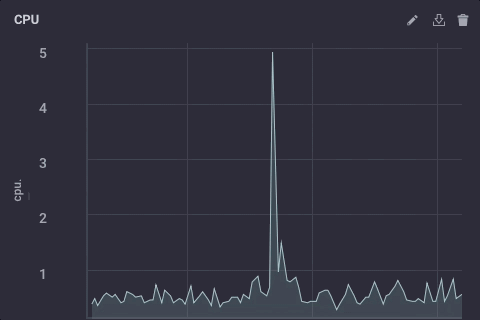
Les données sous-échantillonnées sur mon apparence d’exemple en amont comme celui-ci:
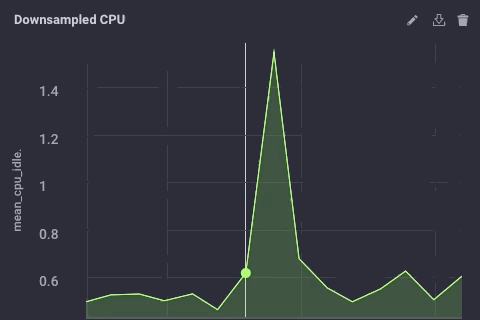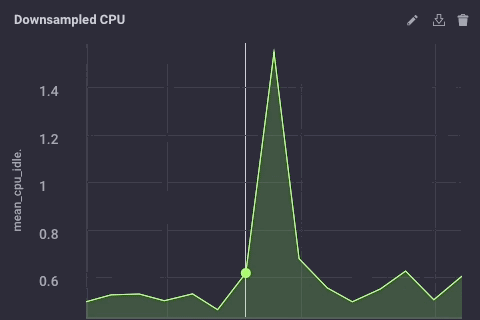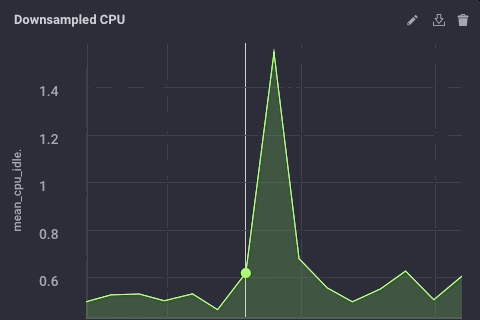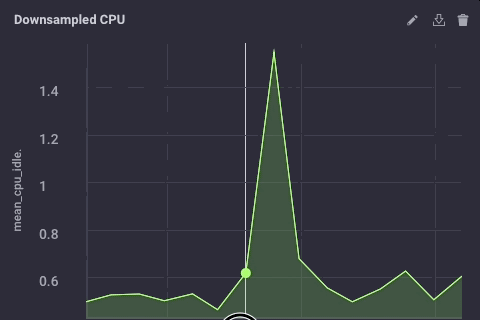
Il est les mêmes données, juste beaucoup moins granulaire. Enfin, je vais définir la stratégie de conservation des données sur mon appareil de passerelle pour être juste 1 jour, donc je ne remplit pas l’appareil, mais je ne peux toujours maintenir un peu d’histoire locale:
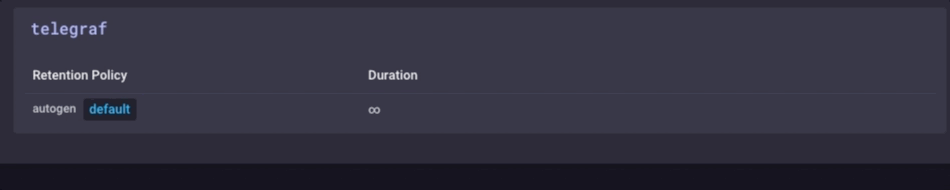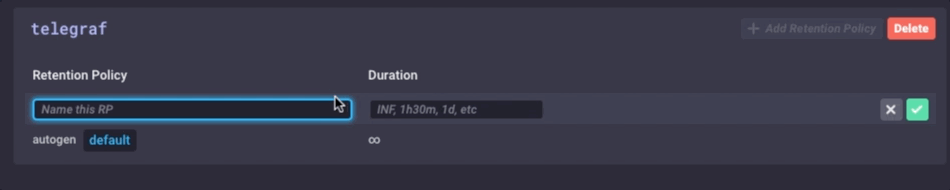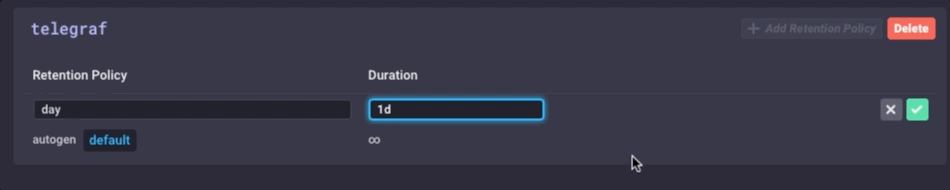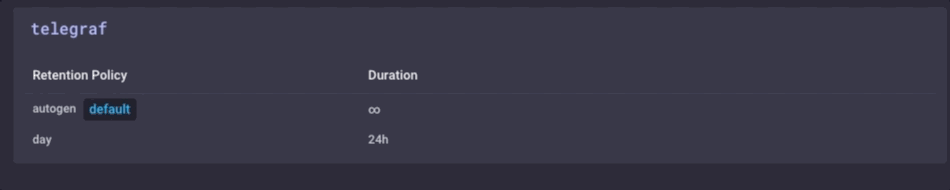
J’ai maintenant un dispositif passerelle IdO qui peut collecter des données de capteur local, présenter quelques analyses à un utilisateur local, faire un peu d’alerte locale (une fois que je mis en place des alertes kapacitor), puis Downsample les données locales et l’envoyer en amont pour mon entreprise InfluxDB par exemple pour une analyse ultérieure et de traitement. Je peux avoir les données milliseconde hautement granulaires disponibles sur le dispositif de passerelle, et les données moins granulaires 1 minute sur mon appareil en amont me permettant d’avoir encore un aperçu des capteurs locaux sans avoir à payer les coûts de bande passante pour envoyer toutes les données en amont.
Je peux également utiliser cette méthode pour la chaîne en outre le stockage de données en stockant les données de 1 minute sur une instance de InfluxDB régional, et la transmission d’autres données, sous-échantillonné à une instance InfluxDB où je peux agréger mes données de capteur à travers mon ensemble de l’entreprise.
Je pouvais ** ** il suffit d’envoyer toutes les données de la chaîne à mon ultime aggrégateur de données d’entreprise, mais si j’agrégeant des dizaines de milliers de capteurs et de leurs données, les coûts de stockage et de bande passante peut commencer à l’emporter sur l’utilité du hautement nature granulaire des données.
Conclusion
Je le répète si souvent que je pourrais avoir tatoué sur mon front, mais je vais le dire encore une fois: IdO données est vraiment utile que si elle est opportune, exacte et *** action **. * Le plus vos données, moins une action, il devient. Moins une action est, le moins de détails dont vous avez besoin. Downsampling vos données, et la mise de plus en plus plus des politiques de conservation des données que vous allez, peut assurer que vos données très immédiate a la particularité d’être très exploitables et très précis, tout en préservant les tendances à long terme dans vos données pour l’analyse des tendances à long terme.