
David G. Simmons
jeudi 25 juin 2020
« Qu'est-ce qui se passe quand vous mettez votre base de données SQL sur Internet »
Et puis nous avons mis en ligne à Hacker Nouvelles.
Si vous écoutez bien, à peu près tout le monde rationnel, ils vous diront sans ambages que la dernière chose que vous voulez jamais faire est de mettre votre base de données SQL sur Internet. Et même si vous êtes assez fou pour faire cela, vous auriez certainement jamais aller poster l’adresse sur un endroit comme Hacker Nouvelles. Non, sauf si vous étiez masochiste de toute façon.
Nous l’avons fait bien, et nous ne sommes même pas un peu désolé à ce sujet.
L’idée
QuestDB a construit ce que nous pensons est le plus rapide Open Source base de données SQL dans l’existence. Nous faisons vraiment. Et nous sommes très fiers, en fait. Tant et si bien que nous voulions donner quelqu’un qui voulait l’occasion une chance de le prendre pour un spin. Avec des données réelles. Faire des requêtes réelles. Presque tout le monde peut rassembler une démo qui fonctionne très sous juste les bonnes conditions, avec tous les paramètres contrôlés étroitement.
Mais ce qui se passe si vous lâchez les hordes là-dessus? Qu’advient-il si vous laissez quelqu’un requêtes d’exécution contre elle? Eh bien, nous pouvons vous dire, maintenant.
Ce que c’est
Tout d’abord, il est une base de données de séries chronologiques basées sur SQL, construit à partir du sol pour la performance. Il est conçu pour stocker et requête très grandes quantités de données très rapidement.
Nous avons déployé sur un serveur AWS c5.metal dans le Londres, Royaume-Uni centre de données (désolé tout ce que vous les Américains du Nord, il y a un certain temps d’attente intégré en raison des lois de la physique). Il a été configuré avec 196GB de RAM, mais nous ne l’utilisait 40GB à l’utilisation de pointe. Le exemple c5.metal fournit 2 CPU 24-noyau (48 coeurs), mais nous avons utilisé une d’entre elles (24 coeurs) sur 23 fils. Nous avons été vraiment pas partout et sur * * près du plein potentiel de cette instance AWS. Cela ne semble pas à la matière du tout.
Les données sont stockées sur un volume EBS AWS qui permet d’accéder aux données SSD. Ce n’est pas tout dans la mémoire.
Les données sont l’ensemble de base de données Taxi NYC ainsi que des données météorologiques associées. Il revient à 1,6 milliard d’enregistrements, pesant environ 350 Go de données. C’est beaucoup. Et il est trop pour stocker en mémoire. Il est trop cache.
Nous avons fourni des requêtes cliquables pour obtenir les gens ont commencé (aucun des résultats ont été mis en mémoire cache ou précalculée), mais nous avons essentiellement n’a pas limité les types de requêtes que les utilisateurs puissent courir. Nous voulions voir, et permettre aux utilisateurs de voir, comment cela réalisé sur tout ce qu’ils requêtes ont jeté à elle.
Il n’a pas été décevant!
The Hacker Nouvelles Poster
Il y a quelques semaines, nous avons écrit sur la façon dont nous avons mis en SIMD instructions pour agréger un milliard de lignes en millisecondes [1] en grande partie grâce à la bibliothèque VCL de Agner Fog [2]. Bien que la portée initiale était limitée aux agrégats de table à l’échelle en une valeur scalaire unique ce fut un premier pas vers des résultats très prometteurs sur des agrégations plus complexes. Avec la dernière version de QuestDB, nous étendons ce niveau de performance à base agrégations clés.
Pour ce faire, nous avons mis la table de hachage rapide de Google alias « Swisstable » [3] qui se trouve dans la bibliothèque Abseil [4]. En toute modestie, nous avons trouvé aussi de la place pour accélérer un peu pour notre cas d’utilisation. Notre version de Swisstable est surnommé « rösti », après le plat traditionnel suisse [5]. Il y avait aussi un certain nombre d’améliorations grâce aux techniques proposées par la communauté tels que prélecture (qui est intéressant avéré avoir aucun effet dans le code de la carte elle-même) [6]. En plus de C ++, nous avons utilisé notre système de file d’attente propre écrit en Java pour paralléliser l’exécution [7].
Les résultats sont remarquables: la latence de la milliseconde sur agrégations à clé qui couvrent plus des milliards de lignes.
Nous avons pensé qu’il pourrait être une bonne occasion de montrer nos progrès en faisant cette dernière version disponible pour essayer en ligne avec un jeu de données de pré-chargé. Il fonctionne sur une instance AWS en utilisant 23 threads. Les données sont stockées sur le disque et comprend un ensemble de données de taxi NYC 1,6 milliard de ligne, 10 ans de données météorologiques avec autour de la résolution de 30 minutes et les prix du gaz par semaine au cours de la dernière décennie. L’instance est situé à Londres, pour que les gens en dehors de l’Europe peut rencontrer différentes latences du réseau. Le temps côté serveur est signalé comme « Exécuter ».
Nous fournissons des exemples de requêtes pour commencer, mais vous êtes encouragés à les modifier. Cependant, s’il vous plaît être conscient que tous les types de requête est encore rapide. Certains sont en cours d’exécution encore sous un ancien modèle mono-thread. Si vous trouvez un de ces derniers, vous saurez: il faudra quelques minutes au lieu de millisecondes. Mais l’ours avec nous, c’est juste une question de temps avant que nous fassions ces instantanés aussi bien. Suivant dans notre ligne de mire est agrégations temps seau à l’aide l’échantillon par la clause.
Si vous êtes intéressé à vérifier la façon dont nous l’avons fait, notre code est disponible open-source [8]. Nous sommes impatients de recevoir vos commentaires sur notre travail jusqu’à présent. Mieux encore, nous aimerions entendre plus d’idées pour améliorer encore les performances. Même après des décennies en calcul haute performance, nous sommes toujours en train d’apprendre quelque chose de nouveau chaque jour.
[1]https://questdb.io/blog/2020/04/02/using-simd-to-aggregate-b?ref=davidgsiot …
[2]https://www.agner.org/optimize/vectorclass.pdf
[3]https://www.youtube.com/watch?v=ncHmEUmJZf4
[4]https://github.com/abseil/abseil-cpp
[5]https://github.com/questdb/questdb/blob/master/core/src/main …
[6]https://github.com/questdb/questdb/blob/master/core/src/main …
[7]https://questdb.io/blog/2020/03/15/interthread?ref=davidgsiot
Et puis nous avons mis en ligne le lien vers la base de données en direct.
Et se rassit.
Et vu le trafic entrant.
Et essayé de ne pas paniquer.
Qu’est-il arrivé
Tout d’abord, nous avons fait la première page de Hacker Nouvelles. Ensuite, nous y sommes restés. Pendant des heures*.
Nous avons vu beaucoup de trafic. Je veux dire beaucoup du trafic. Quelque part plus de 20 000 Les adresses IP uniques.
Hors simples requêtes show, nous avons vu 17,128 requêtes SQL avec 2,485 erreurs de syntaxe dans les requêtes. Nous renvoyés presque 40Go de données en réponse aux requêtes. Les temps de réponse étaient phénoménales. réponses sous-seconde à presque toutes les requêtes.
Quelqu’un dans les commentaires de HN a suggéré que les magasins de colonne sont mauvaises à jointures, ce qui a conduit à quelqu’un venir et essayer de se joindre à la table elle-même. Ordinairement, ce serait une décision incroyablement mauvaise.
Le résultat était … pas ce qu’ils attendaient:
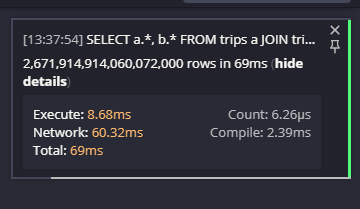
Ouais, c’est 2,671,914,914,060,072,000 lignes. En 69ms (y compris le temps de transfert de réseau). Cela fait beaucoup de résultats dans un très court laps de temps. Certainement pas ce qu’ils attendaient.
Nous avons vu que quelques mauvais acteurs essayer quelque chose de mignon:
2020-06-23T20:59:02.958813Z I i.q.c.h.p.JsonQueryProcessorState [8536] exec [q='drop table trips']
2020-06-24T02:56:55.782072Z I i.q.c.h.p.JsonQueryProcessorState [6318] exec [q='drop *']
Mais ceux ne fonctionnent pas. Nous pouvons être fou, mais nous ne sommes pas naïfs.
Ce que nous avons appris
Il se trouve que lorsque vous faites quelque chose comme ça, on apprend beaucoup. Vous apprenez à connaître vos forces et vos faiblesses. Et vous en apprendre davantage sur ce que les utilisateurs veulent faire avec votre produit ainsi que ce qu’ils vont faire pour essayer de le casser.
Rejoindre la table pour lui-même était une telle leçon. Mais nous avons aussi vu beaucoup de gens utilisent un WHERE clause, ce qui a provoqué des résultats assez lents. Nous par ce résultat, nous avons été surpris pas tout à fait conscience que nous n’avons pas fait les optimisations sur cette voie pour obtenir les résultats rapides que nous voulons. Mais ce fut une grande perspicacité dans la fréquence il est utilisé, et comment les gens utilisent.
Nous avons vu un certain nombre de personnes utilisent le groupe by clause ainsi, et surpris de constater que cela n’a pas fonctionné. Nous aurions probablement dû mis en garde les gens à ce sujet. En bref, groupe by est automatiquement déduit, il est donc pas nécessaire. Mais puisque ce n’est pas mis en œuvre du tout, il provoque une erreur. Nous cherchons donc des façons de gérer cela.
Nous prenons toutes ces leçons à cœur, et faire des plans pour tout adresse que nous avons vu dans les versions à venir.
Conclusions
Il semble que la grande majorité des gens qui ont essayé la démo ont été très impressionné. La vitesse est vraiment à couper le souffle.
Voici quelques-uns des commentaires que nous avons obtenus dans le fil:
J’abusé LEFT JOIN pour créer une requête qui produit 224,964,999,650,251 lignes. 3.68ms Seul le temps d’exécution, maintenant est impressionnant!
Très cool. Major accessoires pour mettre ce là-bas et d’accepter des requêtes arbitraires.
Très impressionnant, je pense que la construction de votre propre base de données (performante) à partir de zéro est l’un des plus impressionnants exploits d’ingénierie du logiciel.
Très cool et impressionnant !! Est pleine compatibilité de fil PostreSQL sur la feuille de route? Je aime la compatibilité postgres :)
(Oui, complète Wire Protocol PostgreSQL est sur la feuille de route!)
Hallucinante, ne savait pas questDB. Le bouton de retour semble cassé sur le chrome mobile
Oui, la démo a fait briser le bouton Précédent de votre navigateur. Il y a une raison réelle pour cela, mais il est vrai, pour l’instant. Nous nous attaquons sans aucun doute que l’un tout de suite.
Essayez vous-même
Vous voulez essayer vous-même? Vous avez lu jusqu’ici, vous devriez vraiment! aller àhttp://try.questdb.io:9000/ pour lui donner un tourbillon.
Nous serions ravis de vous joindre à nous sur notre Communauté Slack Channel, donnez-nous un ([Star GitHub] https://github.com/ questdb / questdb), et), donnez-nous un ([Star GitHub] https://github.com/ questdb / questdb), et Télécharger et essayer vous-même!