
David G. Simmons
jeudi 16 avril 2020
« Ce truc est rapide! »
Je l’ai fait beaucoup de projets en utilisant InfluxDB au cours des dernières années (bien, j’ai travaillé là-bas après tout) alors peut-être que j’ai développé un peu d’un parti pris, ou une tache aveugle. Si vous me suivre sur Twitter, alors vous avez pu me voir poster des vidéos rapides d’un projet, je travaillais pour visualiser Covid-19 données sur une carte.
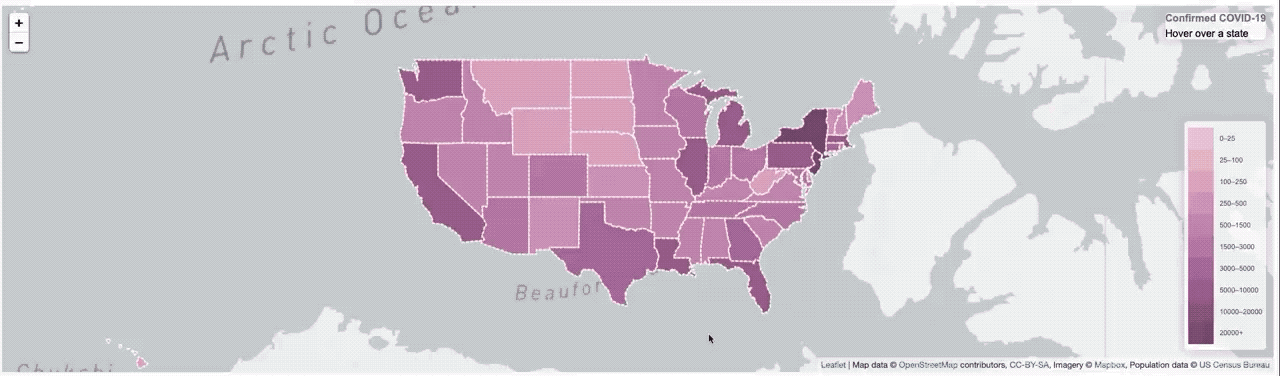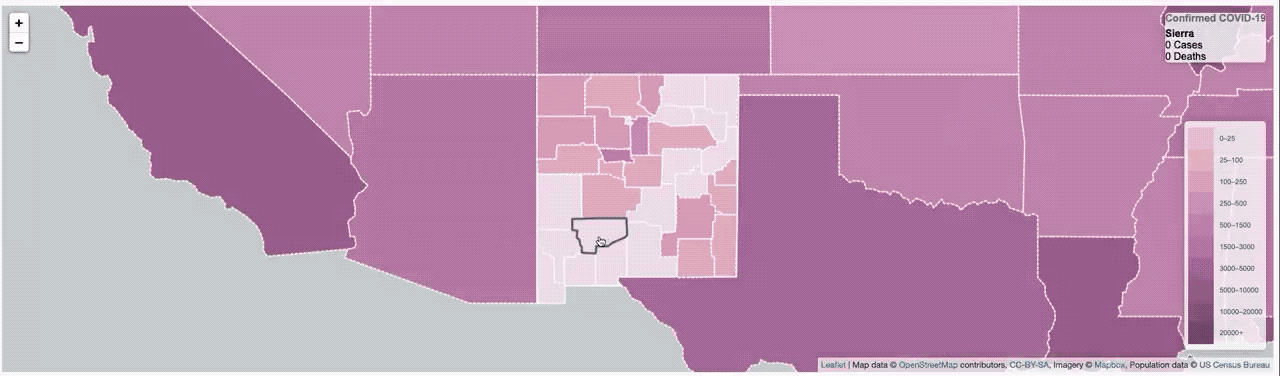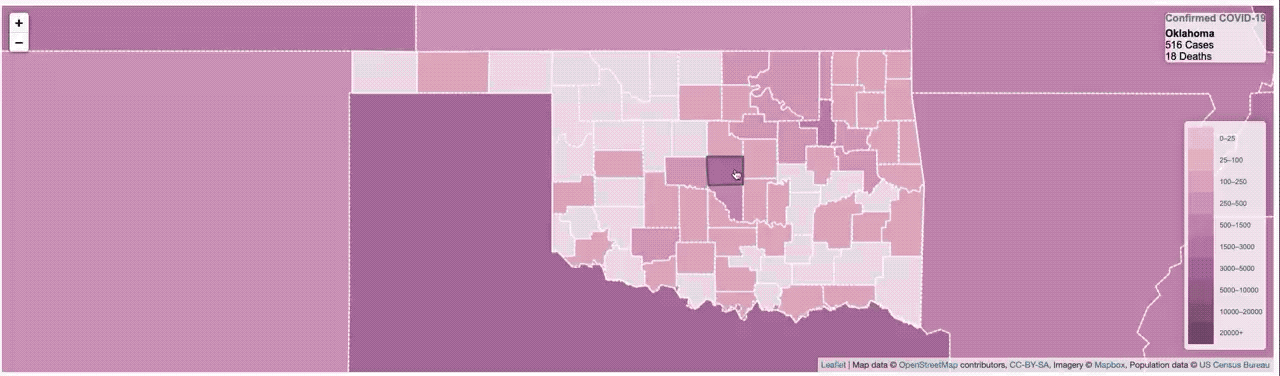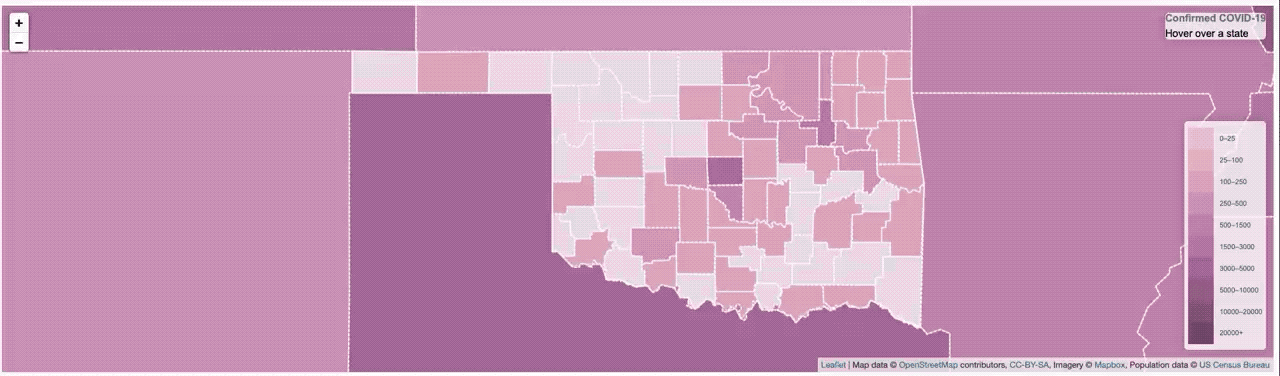 It worked, but it was pretty slow. So much so that I had to put a ’loading’ overlay on it so you knew it was still actually doing something while it was querying the data from the database. I actually sort of thought it was pretty fast, until I started trying to load data from all of Asia, or all of Europe, where that was a lot of data and the query got complicated.
It worked, but it was pretty slow. So much so that I had to put a ’loading’ overlay on it so you knew it was still actually doing something while it was querying the data from the database. I actually sort of thought it was pretty fast, until I started trying to load data from all of Asia, or all of Europe, where that was a lot of data and the query got complicated.
Mais, depuis que je ne fonctionne plus à InfluxData j’ai décidé de se lancer un peu et essayer d’autres solutions. Je veux dire, ce qui est le mal, non? J’ai trouvé ce petit démarrage faire une base de données de séries chronologiques basées sur SQL appelé QuestDB donc je pensais que je lui donnerais un tourbillon. Vraiment petit (essentiellement intégrable) et tout écrit en Java (hey, je faisais Java! Commencé en 1995, en fait!) Donc ce que l’enfer.
Franchement, je suis stupéfait. La performance de cette chose est hallucinant. Il suffit de regarder ceci:
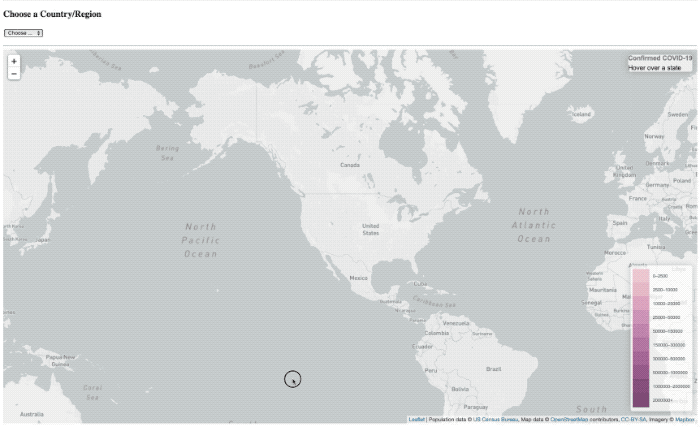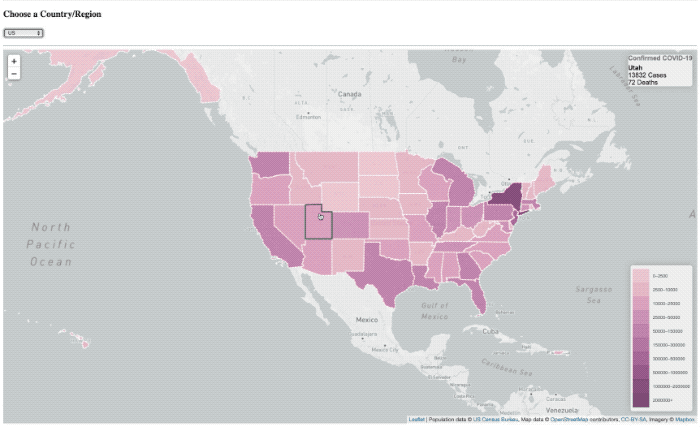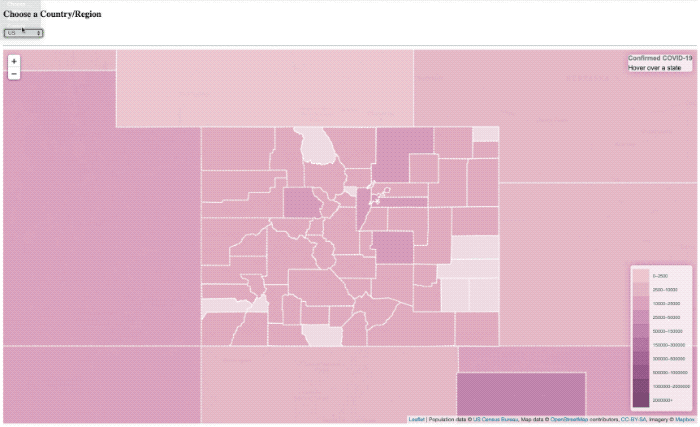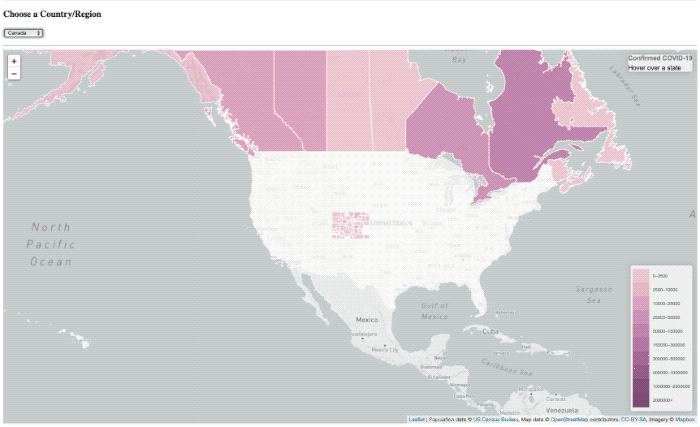
La superposition de « chargement » est toujours là, il a tout simplement ne pas fondamentalement le temps de montrer plus.
De plus, le langage de requête SQL est …. Enfer, même *** I *** sais SQL! Je dois dépoussiérer un peu, car il est fait des années que j’ai écrit tout, mais il est comme le vélo, la plupart du temps.
Vous allez probablement me demander, puisque je fait une grosse affaire sur avant, « oui, mais combien de temps at-il fallu pour le mettre en place? » Je vais vous dire: 30 secondes. Je l’ai téléchargé et exécuté le script questdb.sh de start et … il a été mis en place. Bien sûr, il y avait pas de données, donc je devais charger tout en. Ok, donc combien de temps a fait prendre? Et comment était difficile il? Eh bien, hummm …
J’ai modifié mon programme Go qui avaient tous métamorphosés la John Hopkins Covid-19 les données de leurs fichiers .csv à Afflux fichiers protocole de ligne, donc j’ai passé quelques minutes altérant ** qui ** de façon à tout sortie en un seul, unifié , fichier .csv normalisé (JHU modifie le format de leurs fichiers csv assez souvent, donc je dois continuer à adapter). Une fois que j’avais que je viens de glisser-laissa tomber dans l’interface QuestDB:
Si vous avez manqué cela, il était 77.000 lignes importées en 0,2 secondes.

Oh, et puis je cliqué sur l’icône « vue » et … 77.000 lignes lues en 0,016 secondes. Et ce nombre est ** pas ** une faute de frappe. point zéro-zéro-un-six secondes. Certes, les lignes ne sont pas si grand, mais toujours, qui est rapide contre nature.
Alors maintenant, j’ai un nouveau jouet à jouer avec, et je vais voir ce que je peux faire avec ce qui est amusant, et probablement plus IdO liée.
Restez à l’écoute.