
David G. Simmons
vendredi 13 mars 2020
« Snack suivi avec la nouvelle bibliothèque InfluxDB Arduino »
Une nouvelle bibliothèque
Beaucoup d’entre vous Arduino amateurs sont probablement au courant de la bibliothèque InfluxDB existante qui a été maintenue par Tobias Schürg pendant de nombreuses années. Les chapeaux sont hors de lui fournir cette bibliothèque et le maintenir si longtemps.
Avec l’arrivée de InfluxDB 2.0, il était temps de mettre à jour la bibliothèque. Certains d’entre vous souvenez peut-être que je l’ai fait une mise à jour rapide pour soutenir le InfluxDB 2.0 OSS il y a quelques mois, et qui fonctionnait bien, mais InfluxData travaille à un ensemble de cohérence, ensemble InfluxData entretenu des bibliothèques clientes. Ils ont travaillé avec Tobias au cours des deux dernières mois pour mettre à jour sa bibliothèque avec nos plus récents changements et devenir responsable de cette bibliothèque. Je suis heureux de dire que tout ce travail a payé, et la nouvelle bibliothèque Arduino InfluxDB est officiellement publié, et fait également partie des docs.
Quelques ajouts importants
Cette nouvelle version de la bibliothèque, en arrière compatible avec l’ancienne version (la plupart du temps) a des changements vraiment significatifs pour la version 2.0 de InfluxDB tout en soutenant la ligne de 1.x.
l’écriture par lots est toujours pris en charge, mais il est beaucoup ** ** plus transparente et efficace. Je travaille avec un peu, et il n’y a plus besoin de garder un compteur de lots et d’écrire le lot manuellement. Tout est géré pour vous. Peut-être plus important est la capacité de maintenir la connexion HTTP en vie, ce qui permet d’économiser les frais généraux d’instancier la connexion et déchirer vers le bas à plusieurs reprises. Tant que vous avez WiFi fiable, ce qui est.
Il y a maintenant un soutien pour gérer la pression arrière de la base de données. Si vos écritures ne vont pas à travers, la bibliothèque en cache les écritures qui ont échoué et les essayer à nouveau, et la taille du cache de contre-pression est configurable.
Il y a maintenant un moyen facile de gérer l’horodatage et la synchronisation de temps dans la bibliothèque elle-même. Vous pouvez régler la précision temporelle et la bibliothèque gère automatiquement l’horodatage pour vous.
Il y a beaucoup plus, je suis sûr (y compris la gestion des connexions SSL) que je ne l’ai pas eu à travailler avec, mais je suis sûr que je vais avoir la chance de bientôt!
A Tracker Snack
Étant donné que cette nouvelle bibliothèque vient de sortir, je me suis dit que je mettrais à l’épreuve au moins une fois tout de suite. Pour ce faire, je voulais écrire beaucoup * * des données à travers elle pour voir comment il leva. Pour ce faire, je suis sorti et acheté un peu (https://www.amazon.com/gp/product/B07SX2MYMX/) [DYI Digital Scale] qui utilise un HX711 à l’interface à la cellule de charge. Je me suis alors accroché à un que WEMOS D1 Mini (bien sûr, puisque j’ai beaucoup d’entre eux autour), et j’étais prêt à partir! Je télégraphié vers le haut:
La Bibliothèque Arduino pour le HX711 est venu avec un programme échantillon pour l’étalonnage des échelles, et je sorte de prévu avoir à les calibrer, donc je l’ai acheté un ensemble de poids d’étalonnage quand je l’ai acheté l’échelle. Le programme d’étalonnage enregistre même les données d’étalonnage à l’EEPROM pour vous il est toujours calibré. On dirait qu’il est précis à environ 0,05 gramme, pour la plupart.
Time Code
Maintenant que l’appareil a été construit, il était temps d’écrire un peu de code pour envoyer toutes ces données à InfluxDB! Heureusement, la bibliothèque HX711 est également venu avec un programme échantillon pour seulement crachant des données brutes de l’appareil, donc tout ce que je devais faire était modifier que très légèrement d’envoyer mes données à InfluxDB.
// InfluxDB 2 server url, e.g. http://192.168.1.48:9999 (Use: InfluxDB UI -> Load Data -> Client Libraries)
#define INFLUXDB_URL "influxdb-url"
// InfluxDB 2 server or cloud API authentication token (Use: InfluxDB UI -> Load Data -> Tokens -> <select token>)
#define INFLUXDB_TOKEN "token"
// InfluxDB 2 organization name or id (Use: InfluxDB UI -> Settings -> Profile -> <name under tile> )
#define INFLUXDB_ORG "org"
// InfluxDB 2 bucket name (Use: InfluxDB UI -> Load Data -> Buckets)
#define INFLUXDB_BUCKET "bucket"
InfluxDBClient client(INFLUXDB_URL, INFLUXDB_ORG, INFLUXDB_BUCKET, INFLUXDB_TOKEN);
HX711_ADC LoadCell(D1, D2);
Vous, bien entendu, de définir votre propre URL, TOKEN, etc. Je mis la cellule de charge sur D1 et D2, de sorte que est défini ici aussi.
J’ai ensuite ajouté de routine ce qui suit à la fin de l’installation ():
// Synchronize UTC time with NTP servers
// Accurate time is necessary for certificate validaton and writing in batches
configTime(0, 0, "pool.ntp.org", "time.nis.gov");
// Set timezone
setenv("TZ", "EST5EDT", 1;
influx.setWriteOptions(WritePrecision::MS, 3, 60, true);
Cela crée la synchronisation temporelle, et définit ma précision de temps en millisecondes, définit la taille du lot, la taille de la mémoire tampon (qui dans mon cas je me mis à 3 fois la taille du lot), l’intervalle de rinçage (je fais que le une chasse d’eau se produit au moins toutes les 60 secondes) et je mis le http-keepalive true si je peux utiliser la même connexion à chaque fois.
Cela est d’autant configuration que je devais faire!
Ensuite, je dois écrire les données. Et voici la chose, le programme exemple HX711 lit l’échelle toutes les 250ms
float weight = 0.00;
void loop() {
//update() should be called at least as often as HX711 sample rate; >10Hz@10SPS, >80Hz@80SPS
//use of delay in sketch will reduce effective sample rate (be carefull with use of delay() in the loop)]{style="color: #999dab;"}
LoadCell.update();
//get smoothed value from data set
if(millis() > t + 250) {
float i = LoadCell.getData();
weight = i;
t = millis();
}
writeData(weight);
...
}
void writeData(float weight) {
Point dPoint();
dPoint.addTag("device", "ESP8266");
dPoint.addTag("sensor", SENSOR_ID);
dPoint.addField("weight", weight);
Serial.print("Weight: ");
Serial.println(weight);
if(!influx.writePoint(dPoint)) {
Serial.print("InfluxDB write failed: ");
Serial.println(influx.getLastErrorMessage());
}
Dans le code ci-dessus j’écris un nouveau point de données, avec des étiquettes, etc., tous les ~ 250ms. Vous remarquerez que je viens de continuer à écrire les points de données. Mais en arrière-plan, la bibliothèque gère la mise en lots, la mise en cache, de contre-pression, relances, etc. Je viens de se rendre à datapoints allègrement d’écriture sans y penser plus.
Gummy Bears
Si vous me connaissez tout, vous saurez que je sorte d’une chose * * pour les ours gommeux. J’ai donc décidé de tester cette chose en le chargeant avec un bol d’ours gommeux, et en regardant les données que je les ai mangé. Et voilà, ça marche!
Vous pouvez voir que quand je colle ma main dans le bol pour obtenir certains, le poids monte un peu, puis gouttes. Bien sûr, je devais faire un tableau de bord Gummy Bear:
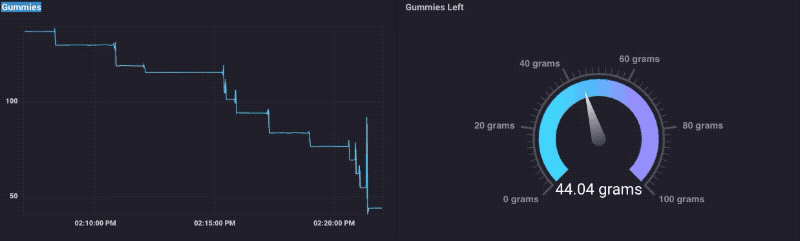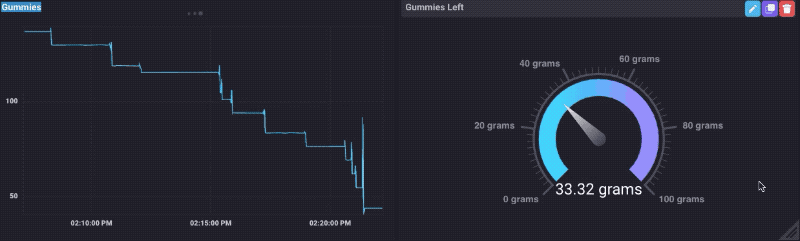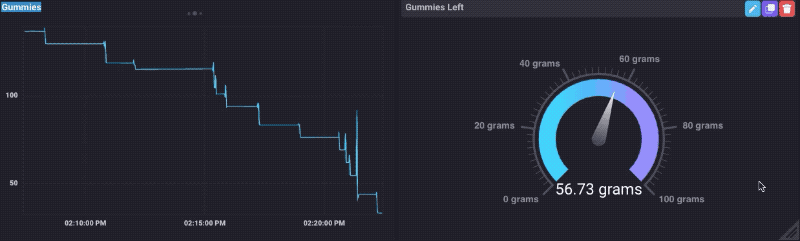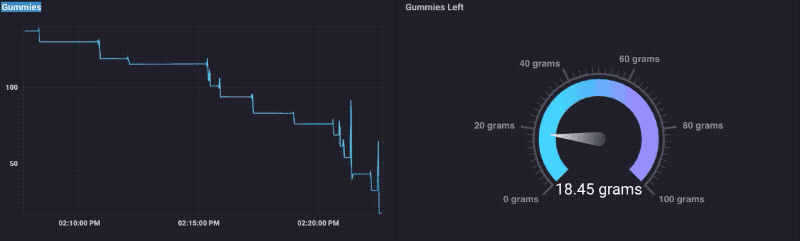
Ce qui était vraiment une sorte de plaisir, jusqu’à ce que je suis sorti des ours gommeux.
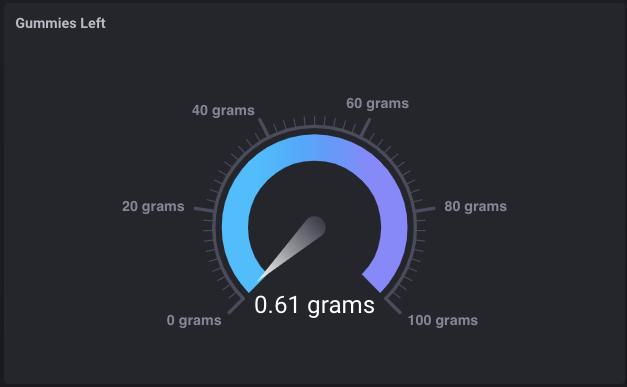
Jusqu’à présent, cette chose a fonctionné pendant quelques heures et je dois encore voir un message d’erreur ou le hoquet de l’appareil lui-même, il semble que le traitement par lots, en tant que cache, etc. est tout fonctionne parfaitement.