
David G. Simmons
jeudi 5 décembre 2019
« IdO données provenant d'autres sources MySQL »
Si vous avez déployé une solution IdO, vous avez dû décider où et comment, pour stocker toutes vos données. Au moins de mon point de vue, le meilleur bien sûr, InfluxDB et le plus de place pour stocker les données du capteur est. Mon disant ne peut pas venir comme une surprise pour vous. Mais les autres données * * dont vous avez besoin pour stocker? Les données sur les * * les capteurs? Des choses comme le fabricant du capteur, la date a été mis en service, le numéro de client, quel type de plate-forme, il est en cours d’exécution sur. Vous savez, toutes les métadonnées du capteur.
Une solution, bien sûr, est d’ajouter simplement tout ce genre de choses en tant que balises à vos données de capteur dans InfluxDB et continuer votre journée. Mais trouvez-vous * vraiment * veulent stocker toutes vos données de capteur avec chaque point de données? Beaucoup de choses semblent être une bonne idée à l’époque, mais délèguent rapidement dans une très mauvaise idée quand la réalité frappe. Comme la plupart de ces métadonnées ne change pas souvent, et peut également être associée à l’information à la clientèle, le meilleur endroit car il est très probable dans un SGBDR traditionnel. Très probablement, vous avez déjà * * un SGBDR avec les données clients dans, alors pourquoi ne pas simplement continuer à l’effet de levier que l’investissement? Comme je l’ai dit à plusieurs reprises, c’est ** pas ** le meilleur endroit pour vos données de capteur. Alors maintenant, vous avez vos données IdO dans deux bases de données différentes. Comment avez-vous accès et fusionner dans un endroit où vous pouvez voir tout cela?
Flux est la réponse
Dites-moi que vous avez vu que venir. Il fallait avoir le voir venir. Ok, pour être juste, vous pouvez avoir parce que, après tout, comment allez-vous pour obtenir vos données basées sur SQL via Flux? C’est la beauté de flux: il est extensible! Nous avons donc maintenant une extension qui vous permet de lire les données de MySQL soit, MariaDB ou Postgres via Flux. Quand j’ai entendu que ce connecteur SQL était prêt à aller, je devais juste essayer. Je vais vous montrer ce que je construit, et comment.
Construire une base de données clients
La première chose à faire était de construire une base de données MySQL avec des informations client. J’ai créé une nouvelle base de données appelée IoTMeta dans laquelle je mets une table avec des métadonnées du capteur. J’ai aussi ajouté une autre table avec des informations client au sujet de ces capteurs.

tables de base jolies, vraiment. Le champ Sensor_ID I avec des données correspondant à la balise Sensor_id dans mon exemple InfluxDB. Je parie que vous pouvez voir où je vais avec cela déjà. J’ai ajouté un tas de données:

Alors maintenant, ma base de données de métadonnées de capteur possède des informations sur chaque capteur, je suis en cours d’exécution ici, ainsi que des « données clients » au sujet de qui est propriétaire des capteurs. Maintenant, il est temps de tirer tout cela en quelque chose d’utile.
Rechercher les données avec Flux
Tout d’abord, je construit une requête dans Flux pour obtenir certains de mes données de capteur, mais je ne réellement intéressés par les données du capteur lui-même. Je cherchais une identification valeur Tag: Sensor_id. Cette requête va chercher un peu étrange, mais il sera logique à la fin, je vous le promets.
temperature = from(bucket: "telegraf")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r._measurement == "temperature" and (r._field == "temp_c"))
|> last()
|> map(fn: (r) => {
return { query: r.Sensor_id }
})
|> tableFind(fn: (key) => true) |> getRecord(idx: 0)
Il retourne une table d’une ligne, et tire ensuite la balise Sensor_id, et c’est là, vous êtes probablement dire « Whaaaat? » Rappelez-vous: Flux retourne tout dans les tableaux. Ce que je dois est essentiellement une valeur scalaire de cette table. Dans ce cas, il est une valeur de chaîne pour la balise en question. Voilà comment vous faites cela.
Ensuite, je vais obtenir le nom d’utilisateur et mot de passe pour ma base de données MySQL, qui est commodément stocké dans les secrets InfluxDB Store.
uname = secrets.get(key: "SQL_USER")
pass = secrets.get(key: "SQL_PASSW")
Attendez, comment ai-je ces valeurs dans ce magasin peuvent Secrets de toute façon? Droit, revenons en arrière d’une minute.
curl -XPATCH http://localhost:9999/api/v2/orgs/<org-id>/secrets -H 'Authorization: Token <token>' -H 'Content-type: application/json' --data '{ "SQL_USER": “<username>" }'
Une chose à noter est que vous obtenez le <org-id> De votre URL. Il est ** pas ** le nom réel de votre organisation dans InfluxDB. Ensuite, vous faites la même chose pour le secret de SQL_PASSW. Vous pouvez les appeler tout ce que vous voulez, vraiment. Maintenant, vous ne devez pas mettre votre nom d’utilisateur / mot de passe en clair dans votre requête.
Ensuite, je vais utiliser tout cela pour construire ma requête SQL:
sq = sql.from(
driverName: "mysql",
dataSourceName: "${uname}:${pass}@tcp(localhost:3306)/IoTMeta",
query: "SELECT * FROM Sensor_data, Customer_Data WHERE Sensor_data.Sensor_ID = ${"\""+temperature.query+"\" AND Sensor_data.measurement = \"temperature\" AND Sensor_data.CustomerID = Customer_Data.Customer_ID"}" //"SELECT * FROM Sensor_data WHERE Sensor_ID = ${"\""+temperature.query+"\" AND measurement = \"temperature\""}" //q // humidity.query //"SELECT * FROM Sensor_Data WHERE Sensor_ID = \"THPL001\""// humidity.query
)
Vous verrez que j’utilise la valeur de ma première requête Flux dans la requête SQL. Frais! Vous remarquerez aussi que je suis un join effectuez dans cette requête SQL afin que je puisse obtenir des données à partir de deux tables * * dans la base de données. À quel point cela est cool? Ensuite, je vais mettre en forme la table résultante d’avoir juste les colonnes que je veux afficher:
fin = sq
|> map(fn: (r) => ({Sensor_id: r.Sensor_ID, Owner: r._Sensor_owner, Manufacturer: r.Sensor_mfg, MCU_Class: r.MCU_class, MCU_Vendor: r.MCU_vendor, Customer: r.Customer, Address: r.Address, Phone: r.phone}))
J’ai maintenant une table qui contient toutes les métadonnées de mon capteur, ainsi que toutes les données de contact client au sujet de ce capteur. Il est temps pour un peu de magie:
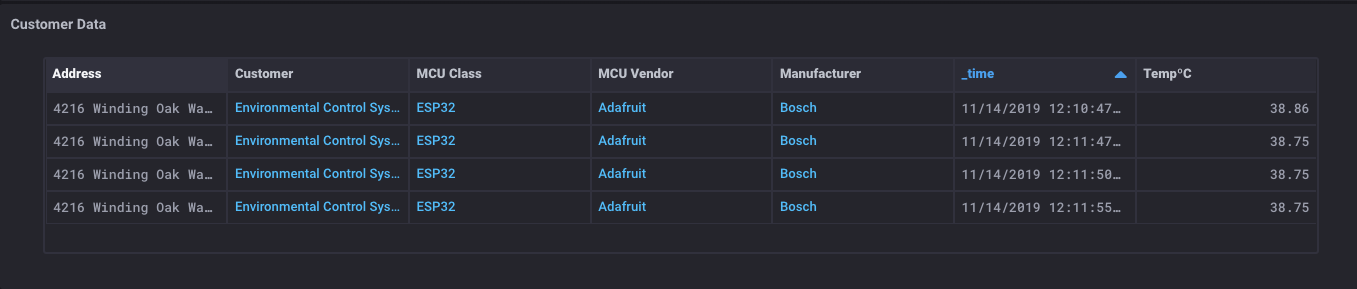
Quelle est cette sorcellerie? J’ai une table qui a toutes les métadonnées sur le capteur, certaines données de clients, ** et ** les lectures du capteur aussi? Ouais. Je fais. Et voici la chose vraiment magique: Puisque vous pouvez obtenir des données à partir des deux bases de données SQL * et * seaux InfluxDB, vous pouvez également joindre ces données ensemble dans une seule table.
Voici comment je l’ai fait:
temp = from(bucket: "telegraf")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r._measurement == "temperature" and (r._field == "temp_c"))
Obtient-moi une table des données du capteur. J’ai déjà une table des métadonnées de SQL, alors …
j1 = join(tables: {temp: temp, fin: fin}, on: ["Sensor_id"] )
|> map(fn: (r) => ({_value: r._value, _time: r._time, Owner: r.Owner, Manufacturer: r.Manufacturer, MCU_Class: r.MCU_Class, MCU_Vendor: r.MCU_Vendor, Customer: r.Customer, Address: r.Address, Phone: r.phone}))
|> yield()
Je viens de joindre ces deux tables sur un élément commun (le champ Sensor_id) et j’ai une table qui a tout en un seul endroit!
Il y a un certain nombre de façons que vous pouvez utiliser cette capacité de fusionner des données provenant de différentes sources. J’aimerais savoir comment vous mettre en œuvre quelque chose comme ceci pour mieux comprendre vos déploiements de capteurs.
Je l’ai fait tout cela en utilisant la construction Alpha18 de InfluxDB 2.0, qui est ce que je lance - en fait je personnalisé construire ma version de la master parce que j’ai quelques ajouts au flux que je l’utilise, mais c’est un tout autre poste. Pour ce genre de choses, l’Alpha construit des logiciels libres InfluxDB 2.0 fonctionnent très bien. Vous devez absolument essayer!