



David G. Simmons
March 24, 2022
Passer à Camunda Cloud
Un peu de contexte
J’ai écrit un peu sur l’utilisation de Camunda pour faire toutes sortes de choses à partir de [l’automatisation des processus IoT](https://davidgs.com/posts/category/camunda /automating-iot-camunda/) pour aider à la gestion d’une communauté Slack. Ok, donc je n’ai pas écrit sur toutes ces choses, mais je les ai certainement faites.
Dans tous ces projets, j’ai utilisé Camunda Platform 7 pour déployer et exécuter mes processus, mais la plupart du travail réel a été effectué par des tâches externes que j’ai écrites en Golang . Ce n’est décidément pas la façon dont j’étais censé faire les choses. La plupart des utilisateurs de Camunda Platform écrivent tout en Java. J’utilise Java depuis avant sa sortie par Sun Microsystems en 1995 (un moment de silence s’il vous plaît pour une entreprise fantastique qui a changé l’industrie, s’il vous plaît).
J’étais un “Technologue Java” en 1996, un travail que nous appellerions maintenant soit un évangéliste, soit un Developer Advocate. Mais ce n’est pas le sujet. Le fait est que même avec cette histoire avec Java, je n’ai pas écrit de code Java significatif depuis plus de 10 ans. Mais j’écris maintenant beaucoup de code Go, alors voici où nous en sommes.
Dernier élément de contexte : j’ai récemment essayé de m’enseigner React.js avec un certain succès (principalement limité). Ainsi, lorsqu’un autre membre de l’équipe a demandé de l’aide pour automatiser le transfert de données de Orbit vers Airtable, j’ai pensé voir si je pouvais écrire un bureau React Application pour le faire.
Écrire l’application React
Ce n’était vraiment pas une application compliquée à écrire. Appelez l’API Orbit pour obtenir les données demandées, reformatez-les un peu, puis appelez l’API Airtable pour les enregistrer. Assez simple.
Voici à quoi ressemble l’application :
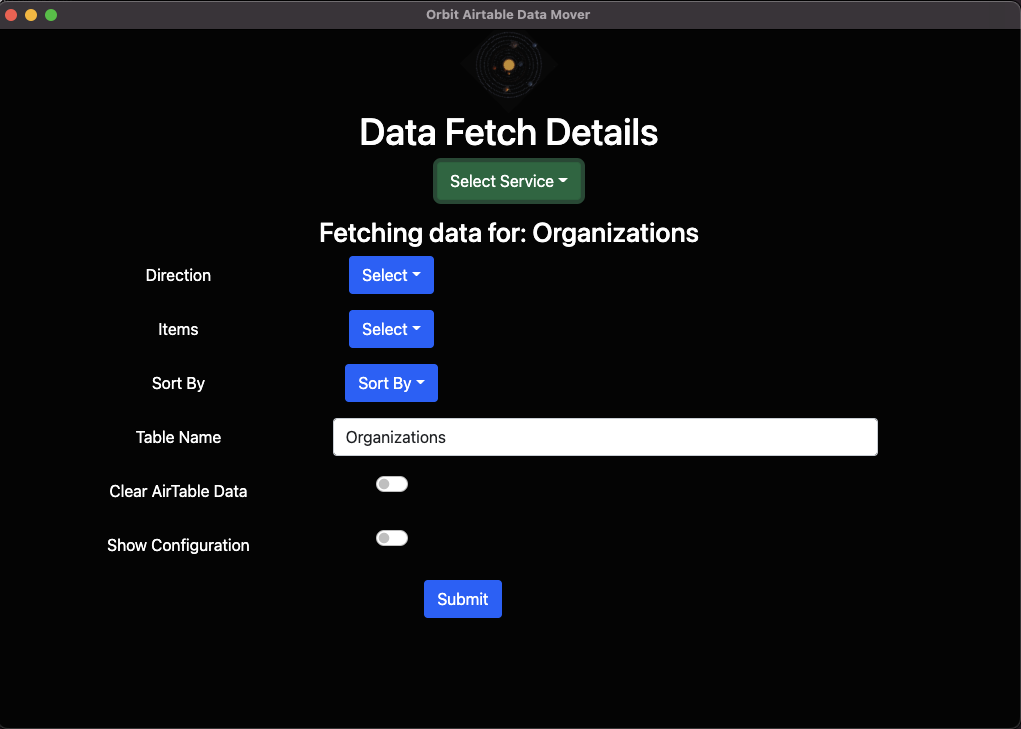
Agréable et simple. Et il y a un petit curseur qui vous montrera la configuration de l’application pour des choses comme les jetons d’authentification, etc.
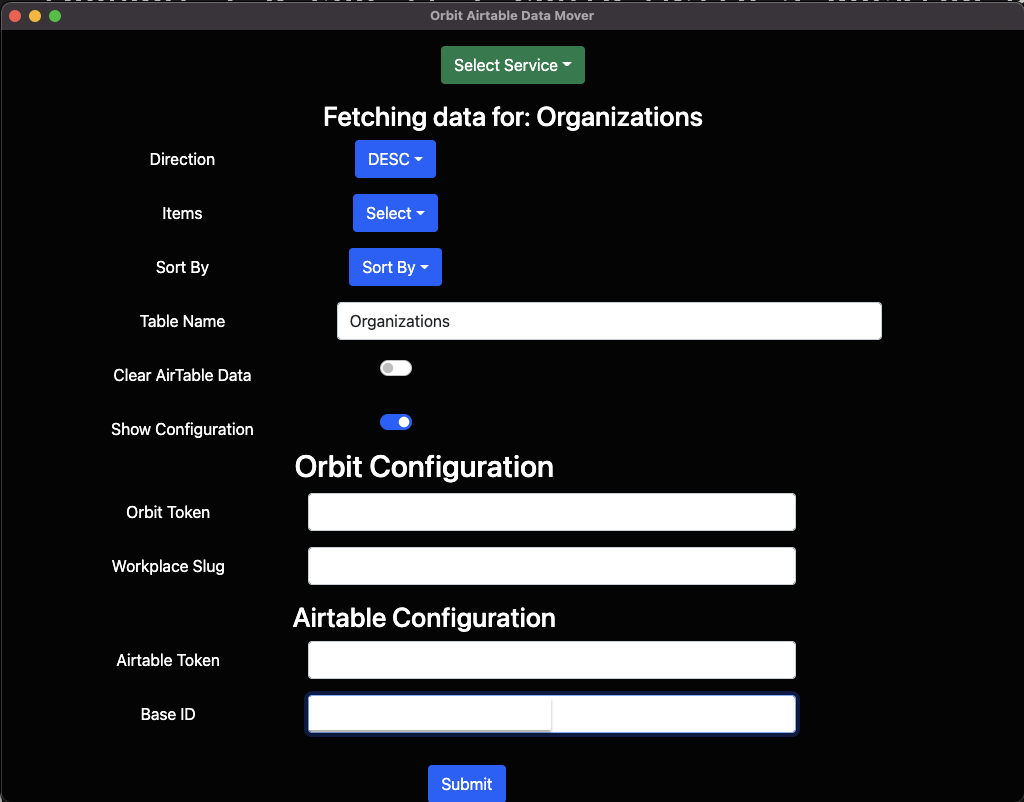
En passant, j’ai choisi la violence un jour et j’en ai fait l’interface utilisateur :
Je ne suis pas fier des choix que j’ai faits ce jour-là.
Donner un tourbillon à Camunda Cloud
Le lendemain de la livraison de l’application à ma collègue, elle est revenue et a dit “Mary a demandé si cela utilise Camunda Cloud.”
À l’origine, j’avais créé l’application à l’aide de Camunda Platform 7, mais la publication directe de l’application React sur Camunda Platform s’avérait problématique, alors j’ai tout simplement contourné Camunda.
Mais depuis qu’on m’a demandé si j’utilisais Camunda Cloud, j’ai décidé de voir si je pouvais utiliser Camunda Cloud ! J’ai donc d’abord trouvé ce diagramme BPMN super compliqué :

Ça ne devient pas plus simple que ça, n’est-ce pas ?
J’ai déployé ce processus simple sur Camunda Cloud, puis j’ai commencé à écrire les gestionnaires correspondants.
Gestion de Camunda Cloud
J’étais super content de voir que l’une des bibliothèques disponibles pour Camunda Cloud était une bibliothèque Golang ! Oh Happy Day!!
import (
"github.com/camunda-cloud/zeebe/clients/go/pkg/entities"
"github.com/camunda-cloud/zeebe/clients/go/pkg/worker"
"github.com/camunda-cloud/zeebe/clients/go/pkg/zbc"
)
M’a donné toute la bonté Go dont j’aurais besoin pour me connecter à Camunda Cloud. Une chose que j’ai rencontrée était que la bibliothèque Go suppose que toutes les variables de connexion au cloud sont enregistrées dans des variables d’environnement. J’ai négligé de le remarquer au début, j’ai donc enregistré toutes mes informations d’identification dans un fichier config.yaml et … cela ne fonctionnait toujours pas. Oh oui, les variables d’environnement.
type ENV struct {
ZeebeAddress string `yaml:"zeebeAddress"`
ZeebeeClientID string `yaml:"zeebeeClientID"`
ZeebeClientSecret string `yaml:"zeebeeClientSecret"`
ZeebeAuthServer string `yaml:"zeebeAuthServer"`
}
var config = ENV{}
func init(){
dat, err := ioutil.ReadFile("path/to/config/zeebe.yaml")
if err != nil {
log.Fatal("No startup file: ", err)
}
err = yaml.Unmarshal(dat, &config)
if err != nil {
log.Fatal(err)
}
config.ZeebeAddress = os.Getenv("ZEEBE_ADDRESS")
if config.ZeebeAddress == "" {
a.init_proc()
os.Setenv("ZEEBE_ADDRESS", config.ZeebeAddress)
os.Setenv("ZEEBE_CLIENT_ID", config.ZeebeeClientID)
os.Setenv("ZEEBE_CLIENT_SECRET", config.ZeebeClientSecret)
os.Setenv("ZEEBE_AUTH_SERVER", config.ZeebeAuthServer)
}
client, err := zbc.NewClient(&zbc.ClientConfig{
GatewayAddress: config.ZeebeAddress,
})
if err != nil {
panic(err)
}
jobWorker := client.NewJobWorker().JobType("fetch_data").Handler(a.handleJob).Open()
go func() {
<- readyClose
jobWorker.Close()
jobWorker.AwaitClose()
}()
}
J’ai décidé de garder ce petit bit de configuration puisque j’exécuterais ce processus en tant que service système, et je ne voulais pas m’occuper des variables d’environnement pour un service système.
Une fois que j’avais initialisé le client, j’ai dû configurer un gestionnaire pour le lancement d’un processus (j’expliquerai comment j’ai lancé le processus dans une minute). Le gestionnaire de processus jobWorker écoute les tâches appelées fetch_data et lorsqu’il en reçoit une, il appelle handleJob pour s’en occuper. Il utilise un canal à l’intérieur d’une fonction afin que je puisse gérer plusieurs demandes simultanément, si j’en ai besoin.
Démarrage d’un processus
Comme j’avais des problèmes avec Camunda Platform et les en-têtes CORS, j’avais besoin d’écrire un processus serveur capable de gérer les requêtes entrantes de l’application.
// The URLs I will accept, handle OPTIONS for CORS
func (a *App) InitializeRoutes() {
a.Router.HandleFunc("/myEndPoint", a.handleOrgs).Methods("OPTIONS", "POST")
}
// Run it!
func (a *App) Run(addr string) {
credentials := handlers.AllowCredentials()
handlers.AllowedHeaders([]string{"X-Requested-With", "Content-Type", "Authorization", "Referer", "Origin"})
methods := handlers.AllowedMethods([]string{"POST", "GET", "OPTIONS"})
origins := handlers.AllowedOriginValidator(originValidator)
log.Fatal(http.ListenAndServeTLS(addr, cert, key, handlers.CORS(credentials, methods, origins, handlers.IgnoreOptions())(a.Router)))
}
// handle the CORS preflight request
func (a *App) handleCORS(w http.ResponseWriter, r *http.Request) {
w.Header().Set("Access-Control-Allow-Origin", "*")
w.Header().Set("Access-Control-Allow-Methods", "POST, GET, OPTIONS, PUT, DELETE")
w.Header().Set("Access-Control-Allow-Headers", "Accept, Content-Type, Content-Length, Accept-Encoding, X-CSRF-Token, Authorization")
}
// handle the incoming request
func (a *App) handleOrgs(w http.ResponseWriter, r *http.Request) {
if r.Method == "OPTIONS" {
a.handleCORS(w, r) // preflight
return
}
if r.Header.Get("Content-Type") != "" {
value, _ := header.ParseValueAndParams(r.Header, "Content-Type")
if value != "application/json" {
msg := "Content-Type header is not application/json"
http.Error(w, msg, http.StatusUnsupportedMediaType)
return
}
}
body, err := ioutil.ReadAll(r.Body)
if err != nil {
fmt.Println(err)
}
// limit to 1MB
r.Body = http.MaxBytesReader(w, r.Body, 1048576)
pdat := ProcessData{}
err = json.Unmarshal(body, &pdat)
dec := json.NewDecoder(r.Body)
if err != nil {
var syntaxError *json.SyntaxError
var unmarshalTypeError *json.UnmarshalTypeError
switch {
// Catch any syntax errors in the JSON
case errors.As(err, &syntaxError):
msg := fmt.Sprintf("Request body contains badly-formed JSON (at position %d)", syntaxError.Offset)
http.Error(w, msg, http.StatusBadRequest)
// In some circumstances Decode() may also return an
// io.ErrUnexpectedEOF error for syntax errors in the JSON.
case errors.Is(err, io.ErrUnexpectedEOF):
msg := "Request body contains badly-formed JSON"
http.Error(w, msg, http.StatusBadRequest)
// Catch any type errors We can interpolate the relevant
// field name and position into the error
// message to make it easier for the client to fix.
case errors.As(err, &unmarshalTypeError):
msg := fmt.Sprintf("Request body contains an invalid value for the %q field (at position %d)", unmarshalTypeError.Field, unmarshalTypeError.Offset)
http.Error(w, msg, http.StatusBadRequest)
// Catch the error caused by extra unexpected fields in the request body
case strings.HasPrefix(err.Error(), "json: unknown field "):
fieldName := strings.TrimPrefix(err.Error(), "json: unknown field ")
msg := fmt.Sprintf("Request body contains unknown field %s", fieldName)
http.Error(w, msg, http.StatusBadRequest)
// An io.EOF error is returned by Decode() if the request body is
// empty.
case errors.Is(err, io.EOF):
msg := "Request body must not be empty"
http.Error(w, msg, http.StatusBadRequest)
// Catch the error caused by the request body being too large.
case err.Error() == "http: request body too large":
msg := "Request body must not be larger than 1MB"
http.Error(w, msg, http.StatusRequestEntityTooLarge)
// Otherwise default to logging the error and sending a 500 Internal
// Server Error response.
default:
log.Println(err.Error())
http.Error(w, http.StatusText(http.StatusInternalServerError), http.StatusInternalServerError)
}
return
}
// Call decode again, using a pointer to an empty anonymous struct as
// the destination. If the request body only contained a single JSON
// object this will return an io.EOF error. So if we get anything else,
// we know that there is additional data in the request body.
err = dec.Decode(&struct{}{})
if err != io.EOF {
msg := "Request body must only contain a single JSON object"
http.Error(w, msg, http.StatusBadRequest)
return
}
// error free, we can start the process
err = startProcess(pdat)
if err != nil {
fmt.Println(err)
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
}
func startProcess(pdat ProcessData) error {
client, err := zbc.NewClient(&zbc.ClientConfig{
GatewayAddress: config.ZeebeAddress,
})
if err != nil {
return err
}
// turn the data structure into a map, which is what the Zeebe API expects
var b map[string]interface{}
inter, err := json.Marshal(pdat)
if err != nil {
return err
}
json.Unmarshal([]byte(inter), &b)
// create the process
ctx := context.Background()
request, err := client.NewCreateInstanceCommand().BPMNProcessId("orbit-data").LatestVersion().VariablesFromMap(b)
if err != nil {
return err
}
msg, err := request.Send(ctx)
if err != nil {
return err
}
return nil
}
C’est tout ce qu’il a fallu pour accepter les demandes entrantes de l’application, puis démarrer un processus dans Camunda Cloud.
Gestion de l’achèvement de la tâche
Maintenant que j’ai un moyen de démarrer le processus, je dois gérer les tâches au fur et à mesure qu’elles se produisent.
Si vous vous souvenez plus tôt, j’avais mis en place un gestionnaire de tâches pour le processus :
jobWorker := client.NewJobWorker().JobType("fetch_data").Handler(a.handleJob).Open()
go func() {
<- readyClose
jobWorker.Close()
jobWorker.AwaitClose()
}()
Alors maintenant, il est temps d’écrire toute cette histoire de handleJob.
func (a *App) handleJob(client worker.JobClient, job entities.Job){
jobKey := job.GetKey()
_, err := job.GetCustomHeadersAsMap()
if err != nil {
a.failJob(client, job)
return
}
// get all the submitted variables
variables, err := job.GetVariablesAsMap()
if err != nil {
a.failJob(client, job)
return
}
request, err := client.NewCompleteJobCommand().JobKey(jobKey).VariablesFromMap(variables)
if err != nil {
a.failJob(client, job)
return
}
incomingData := ProcessData{}
jsonStr, err := json.Marshal(variables)
if err != nil {
fmt.Println(err)
}
err = json.Unmarshal(jsonStr, &incomingData)
if err != nil {
fmt.Println("Json unmarshall: ", err)
}
// this is where I get the data from Orbit, and send it to Airtable.
err = handleProcess(incomingData)
if err != nil {
a.failJob(client, job)
return
}
// If all of that works, complete the job
ctx := context.Background()
_, err = request.Send(ctx)
if err != nil {
panic(err)
}
log.Println("Successfully completed job")
//close(readyClose)
}
// Handle failing a job
func (a *App) failJob(client worker.JobClient, job entities.Job) {
log.Println("Failed to complete job", job.GetKey())
ctx := context.Background()
_, err := client.NewFailJobCommand().JobKey(job.GetKey()).Retries(job.Retries - 1).Send(ctx)
if err != nil {
panic(err)
}
}
C’est à peu près ça ! Je ne vous ennuierai pas avec toutes les manigances que j’ai dû traverser pour obtenir les données d’Orbit et dans Airtable, car cela n’est pas entièrement pertinent pour le processus Camunda Cloud.
Une plainte contre Airtable
Je déposerai une grande plainte contre l’API Airtable pour la suppression d’enregistrements d’une table. Bon, peut-être 2.
- Il n’y a aucun moyen d’effacer toutes les données d’une table. Vous ne pouvez supprimer que 10 enregistrements à la fois et vous devez d’abord récupérer toutes les données de la table afin d’obtenir les ID d’enregistrement. Ensuite, allez les supprimer 10 à la fois. C’est une perte de temps et de ressources.
- L’API Airtable pour supprimer des enregistrements est une poubelle.
Les docs disent :
Pour supprimer des enregistrements de table, envoyez une demande DELETE au point de terminaison de table. Notez que les noms de table et les identifiants de table peuvent être utilisés de manière interchangeable. L’utilisation des identifiants de table signifie que les changements de nom de table ne nécessitent pas de modifications de votre demande d’API.
Votre demande doit inclure un tableau codé en URL contenant jusqu’à 10 ID d’enregistrement à supprimer.
Et l’exemple de code fourni par Airtable est :
curl -v -X DELETE https://api.airtable.com/v0/BASE_ID/TABLE_NAME \
-H "Authorization: Bearer YOUR_API_KEY" \
-G \
--data-urlencode 'records[]=rec9mP3czPxkvf9IR' \
--data-urlencode 'records[]=recMxJ0texTTI5BPq'
Je suppose que vous pouvez voir le problème ici. Ce n’est pas un tableau d’ID d’enregistrement !! Vous devez placer chaque ID d’enregistrement sur une ligne distincte, puis envoyer le tout en tant que données application/x-www-form-urlencoded. Et pour une raison stupide, le paramètre d’URL doit s’appeler records[]. Je suppose qu’ils ont décidé d’ajouter le [] pour pouvoir l’appeler un tableau. Ce n’est toujours pas un tableau. Ce n’est tout simplement pas le cas. C’est une colline sur laquelle je mourrai.

J’ai perdu une heure de ma vie là-dessus.
func deleteNow(delData AirtableData) error {
recordCounter := 0
records := make([]string, 10)
// delData is a struct{} that holds all the records to delete
// All of this is because the API doesn't actually take an array
for _, record := range delData.Records {
records[recordCounter] = "records[]=" + record.ID
recordCounter++
if recordCounter == 10 {
urlParm := strings.Join(records, "&")
err = deleteNow(urlParm, incoming)
if err != nil {
return err
}
recordCounter = 0
records = make([]string, 10)
}
}
if recordCounter > 0 {
urlParm := strings.Join(records, "&")
err = deleteNow(urlParm, incoming)
if err != nil {
return err
}
}
return nil
}
func deleteNow(urlParm string, incoming AirtableData) error {
client := &http.Client{}
delReq, err := http.NewRequest("DELETE", "https://api.airtable.com/v0/" + incoming.BaseID + "/" + incoming.TableName + "?" + urlParm, nil)
if err != nil {
return err
}
parseFormErr := delReq.ParseForm()
if parseFormErr != nil {
fmt.Println(parseFormErr)
}
delReq.Header.Add("Authorization", "Bearer " + incoming.AirtableToken)
delReq.Header.Add("Content-Type", "application/x-www-form-urlencoded; charset=utf-8")
_, err = client.Do(delReq)
if err != nil {
fmt.Println("Failure : ", err)
}
return nil
}
Donc, si vous essayez également de supprimer des enregistrements d’une table Airtable, je viens de le résoudre pour vous. Ignorez leurs docs API.
##Conclusions
Camunda Cloud exécute pratiquement tout comme une tâche externe, qui peut être écrite en Golang. Comme c’est comme ça que je faisais tout avant de toute façon, Camunda Cloud va être ma valeur par défaut à partir de maintenant ! Je peux même réécrire un tas de mes processus Camunda Platform pour en faire des processus Camunda Cloud, puisque toute la gestion des tâches est déjà effectuée dans Go.
Au moins pour moi, cette nouvelle façon de mettre en œuvre les choses est très naturelle et fait énormément de sens. Cela correspond parfaitement à ma façon de travailler déjà, donc c’est un plaisir pour moi de continuer à le faire !
J’aimerais entendre ce que vous pensez de cette nouvelle façon de faire, alors n’hésitez pas à laisser des commentaires, etc.!
 Français
Français English
English Deutsche
Deutsche Dutch
Dutch Español
Español