



David G. Simmons
July 14, 2017
Ejecución de InfluxDB en una ARTIK-520
Seamos realistas, la IO se trata de datos. I dije hace tan sólo unas semanas. Se trata de la recopilación de datos. ** ** Un montón de datos. Pero en realidad es sobre mucho más que un simple recopilación de datos. Simplemente la recogida de datos en realidad no llegarán a ninguna parte si todo lo que hacemos es recogerla. Para ser útiles, los datos de la IO tiene que ser adecuada, precisa y procesable. Esa última parte es la clave, la verdad. datos procesables. Con el fin de hacer que su procesable de datos, tiene que ser capaz de analizarla, preferentemente en tiempo real. Ahora sus problemas de datos están creciendo. Tienes un tsunami literal de datos de series de tiempo de vertido en sus gastos y todos sus recursos simplemente ingerirlo. Ahora te estoy diciendo que es necesario analizar también, y tomar acciones sobre la base de ese análisis * en tiempo real * ?! Sal.
No matar al mensajero. Usted es el que quería desplegar una solución de la IO para controlar todos los 10.000 de sus whosiwhatsits, no yo. Pero voy a decir cómo solucionarlo.
No es la ARTIK-520 otra vez!
Sí, el ARTIK-520 de nuevo. Tenía un servidor Linux aquí en la oficina que probablemente habría sido un buen lugar para hacer esto, pero se ha ido a su casa ahora (sólo estaba fomentando y, lo que es útil antes de enviarlo a vivir una vida larga y productiva un servidor de directorio activo. no pida. Nunca vamos a hablar de nuevo). Podría haber usado un Frambuesa Pi, o incluso la Frambuesa Pi cero W que he sentado aquí. Como ya saben, tengo una) que he sentado aquí. Como ya saben, tengo una plétora de los dispositivos IO entre los que elegir. Yo quería algo con un poco más de potencia que un IO * * dispositivo estándar y simplemente no tenía ganas de pelearse con el Pis. Así que usted está atascado audiencia sobre el 520 de nuevo.
Configuración de la ingestión de datos y análisis
Espera, vamos a hacer la ingestión y el análisis de datos en una ARTIK-520? ¿No deberíamos estar utilizando un servidor? Véase más arriba. Además, ¿no sería poco interesante para hacer algo de la ingestión de datos y análisis en el centro, antes de que los datos se envían a la backend? Quizás. Así que eso es lo que vamos a hacer.
Como el título de este post indica, vamos a utilizar InfluxDB de Afluencia de datos. Es de código abierto y libre si quieres probarlo también. No dude en seguir a lo largo. ¿Por InfluxDB? Bueno, quería probarlo, y que afirma ser el más rápido crecimiento de base de datos de series temporales alrededor, además he oído que era bastante fácil de poner en marcha, así que pensé que le daría una oportunidad.
En primer lugar, voy a decir que conseguir todo y correr era sencilla absolutamente muerto. Al igual que su vicepresidente de marketing puede hacerlo (** Broma interior de alerta:. ** En mis días de sol, la construcción de maquetas que estaban instalable y ejecutable por mi VP de Marketing siempre fue mi métrica A él le encantó porque podía correr ellos!) I descargado todos los componentes y les puso en marcha. Hay un montón de piezas móviles aquí, por lo que necesita para asegurarse de que llegar a todos ellos. Hay ** ** InfluxDB, que es (obviamente) la parte de la base de datos. Una especie de clave de todo el asunto. También hay ** ** Telegraf, que es un motor de la ingestión de datos. Luego está ** ** Chronograf, que es una herramienta de visualización y análisis muy ingenioso. Por último hay ** ** Kapacitor que se encarga de toda la parte de “acción” para usted.
Yo era capaz de descargar e instalar todas las partes en unos 5 minutos - tal vez menos - y obtener toda la cosa en marcha y funcionando. Incluso he construido mi primer tablero de instrumentos para monitorear el uso de la CPU y la memoria de la ARTIK-520 en un minuto y medio.
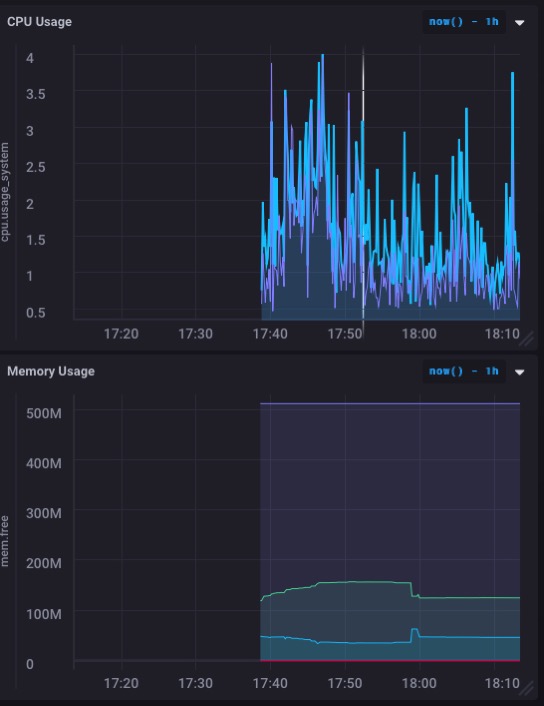
Que en realidad se ve muy bien. Especialmente el gráfico de uso de memoria. Así que probablemente no vuelva a desbordar la memoria con este - y deje de tener en cuenta que todavía me estoy quedando esta ARTIK-520 como un OpenHAB servidor el control de mi casa.
Pero lo que realmente quiero usar esto para el seguimiento de algunos datos de los sensores reales, no sólo la propia máquina. Lo que pasa es que tengo un proyecto sensor de aquí en mi escritorio, y es la recogida de datos de forma activa y registrarlo. Inicio de sesión en otro lugar, pero eso está por cambiar.
Registro de datos en vivo
El sensor ya he establecido y en funcionamiento es un uno que escribí sobre recientemente. Es enganchado a un). Es enganchado a un Particle.io de fotones y es la medición de la cantidad de ‘cosas’ en un cuadro más o menos continua (1 lectura cada segundo). He creado una base de datos para este - ‘iotdata’ ¿verdad original? - y la publicación probado a él desde la línea de comandos de acuerdo con el (excelente)) de fotones y es la medición de la cantidad de ‘cosas’ en un cuadro más o menos continua (1 lectura cada segundo). He creado una base de datos para este - ‘iotdata’ ¿verdad original? - y la publicación probado a él desde la línea de comandos de acuerdo con el (excelente) Documentación. Todo parecía ir según lo previsto. Ahora para obtener datos en tiempo real a raudales!
Primero tenía que hacer un agujero en el cortafuegos para poder llegar a mi caja de ARTIK-520 del mundo exterior. Parece una locura que la partícula se encuentra en un lado de mi escritorio y el ARTIK-520 está en el otro y mis datos tiene que hacer un viaje alrededor del planeta para llegar allí, pero así es como funciona el mundo a veces.
Partícula tiene WebHooks ’’ que puede establecer una cuenta para escribir a otros servicios. Tienen algunos predefinidos para Google Apps, etc., pero ninguno de InfluxDB. Tienen que arreglar eso, pero eso es otro post. He intentado definir mi propia web hook, pero sus ganchos web insisten en publicar todo como
content-type: application/x-www-form-urlencoded
Y eso no es lo que se espera, y resulta que no trabajo. Sin desanimarse, me las arreglé para llegar a otra solución. El dispositivo de partículas publicará sus datos directamente a InlfuxDB. ¿Quién necesita un intermediario! Se necesita un poco más de código, pero no es malo. Esto es lo que he tenido que añadir a mi código de partícula:
#include <HttpClient.h>
...
HttpClient http;
http_header_t headers[] = {
{ "Accept" , "*/*"},
{ "User-agent", "Particle HttpClient"},
{ NULL, NULL } // NOTE: Always terminate headers will NULL
};
http_request_t request;
http_response_t response;
...
void loop(){
...
request.body = String::format("volume_reading value=%d", getRangeReading());
http.post(request, response, headers);
...
}
Eso es todo lo que hizo! Se dará cuenta de que no estoy usando ningún tipo de seguridad en esta configuración. ** No recomiendo hacerlo de esta manera **. Por lo menos usted debe utilizar un nombre de usuario / contraseña para la autenticación de la base de datos, y probablemente debería ser también el uso de SSL. Pero no tengo un certificado SSL para mi ARTIK-520, y esto era sólo un ejercicio de mi parte y no una implementación real. Además Asomé agujeros no estándar en mi firewall, y realmente no creo que nadie va a venir a llamar (y si lo hacen, voy a ver al instante y puede cerrar hacia fuera, así que no te hagas ilusiones).
Y esto es lo que mi tablero ahora queda como:
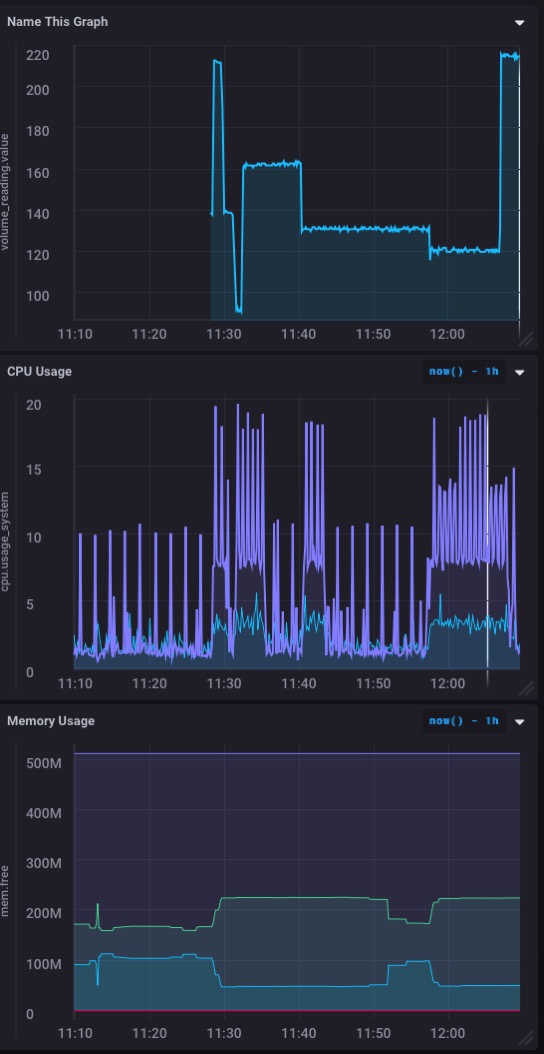
Un buen ** ** en tiempo real gráfica de los datos de entrada de mi sensor. Rápido y fácil de configurar!
Que sea procesable
Hasta ahora, hemos establecido Telegraf para la ingestión de datos, InfluxDB, la base de datos real, y Chronograf que nos da los cuadros de mando frescas de datos en tiempo real desde nuestro sensor (s). Pero, de nuevo, los datos es todo lindo y divertido, pero es la haciéndolo * * procesable que es la clave. Y ahí es donde entra en acción. Kapacitor así que voy a poner esto en marcha el próximo para que pueda recibir alertas y notificaciones cuando el volumen de ‘cosas’ en mi caja es demasiado alto o demasiado bajo.
Kapacitor, por desgracia, no tiene una interfaz pulida interfaz de usuario que se presta fácilmente a ver los resultados de una manera que satisface visualmente. Pero no es menos potente. Sólo tienes que escribir sus ‘acciones’ en TICKScript y luego desplegarlas. Así que sumergirse en la documentación y se les va ya!
La sintaxis de secuencias de comandos TICK es un poco incómoda, así que la verdad es que asegúrese de que usted ha leído la documentación en este caso. Seriamente. Yo era capaz, en unos 10 minutos, para escribir secuencias de comandos 2 TICK de alerta cuando la medición del volumen consiguió por debajo de 50 (que es bastante darned completo!) O cuando se puso por encima de 210 (que es esencialmente vacío). Por ahora, las alertas son simplemente registran en un archivo, pero podría fácilmente les dio la vuelta como un puesto a mi servidor para hacer un aviso del navegador o alguna otra cosa.
Me gustaría ver un front-end de lujo en Kapacitor que hace que la escritura y la implementación de secuencias de comandos TICK rápido y fácil, y que le permite hacer a las alertas y las cosas en su Chronograf cuadros de mando, pero por ahora estoy bastante contento con el envío de alertas simplemente fuera a otras cosas.
Si quisiera, podría enviar dichas alertas ** ** volver a mi Fotón - a través de un POST a la API de partículas de la nube - tener el Photon tomar una acción de su propio también. Tal vez si tuviera un todo neumática ‘impulsor’ eso sería empujar fuera de la caja me gustaría hacer eso.
Tu turno
Con suerte he conseguido que lo suficientemente lejos en el camino que usted puede comenzar su propio proyecto basado InfluxDB para los datos de la IO. Si lo hace, me encantaría saberlo!
 Español
Español English
English Deutsche
Deutsche Dutch
Dutch Français
Français