
David G. Simmons
lunes, 18 de diciembre de 2017
La construcción de un dispositivo de puerta de enlace para la IO local de alerta y datos de disminución de resolución
Hay todo tipo de maneras de arquitecto de la implementación de la IO, y lo que es correcto para una empresa no serán necesariamente para otra. Dependiendo del tamaño y la complejidad de su proyecto de la IO, no puede haber, por supuesto, una gran cantidad de componentes. Una de las arquitecturas más universal es el despliegue de las carreras de sensor o dispositivos de puerta de enlace a datos de tomarse de un número de nodos de sensores y luego hacia adelante que los datos sobre a un sistema de recogida de datos en sentido ascendente para la empresa. Estos dispositivos gateway o hub suelen permitir un dispositivo Z-Wave para conectarse a la Internet para la carga de datos, o puente entre los dispositivos Bluetooth a una conexión Wi-Fi u otra conexión de red.
Además, la mayoría de estos dispositivos de puerta de enlace o de cubo tienden a ser las puertas de enlace ‘muda’. Ellos no hacen distinta de los datos hacia adelante nada a un colector de aguas arriba. Pero lo que si la puerta de enlace IO podría ser un dispositivo inteligente? ¿Qué pasa si usted podría hacer análisis y procesamiento de datos locales en el concentrador ** ** antes de enviar los datos de? No que sea útil!
La construcción de una puerta de enlace
Decidí construir (otro) dispositivo de puerta de enlace de la IO inteligente esta mañana. Tengo (tipo de) construido uno antes en forma de un ARTIK-520 corriendo InfluxDB. Sin embargo, un ARTIK-520 no es lo más barato que hay, y cuando está la construcción de dispositivos IO, a veces más barato es mejor. No siempre, pero cuando está la construcción de montones y montones de puertas de enlace, prefiere no romper el banco en ellos. Saqué mi caja) en forma de un ARTIK-520 corriendo InfluxDB. Sin embargo, un ARTIK-520 no es lo más barato que hay, y cuando está la construcción de dispositivos IO, a veces más barato es mejor. No siempre, pero cuando está la construcción de montones y montones de puertas de enlace, prefiere no romper el banco en ellos. Saqué mi caja Pino-64 que compré hace unos años y se puso a trabajar. ¿Por qué Pino-64 y no Frambuesa Pi? Pues bien, el pino-64 es aproximadamente 1/2 del costo. Sí, el costo medio. Se trata de $ 15 en lugar de $ 35, por lo que hay que. Tiene exactamente el mismo procesador de 1,2 GHz de cuatro núcleos ARM A53 - la mía tiene 2 GB de memoria, frente a la de 1 GB en un RPI - y tiene una GPU más poderosa, si usted está en ese tipo de cosas. También vino con WiFi incorporado, por lo que no dongle, y me dio la tarjeta opcional ZWave para que pueda hablar a los dispositivos sub-GHz de IO.
Una de las cosas buenas acerca de la ejecución de este tipo de dispositivos como la IO Pasarelas es que sólo está limitado en su almacenamiento por el tamaño de la tarjeta microSD que utilice. Sólo estoy usando una tarjeta de 16 GB, pero el pino-64 puede llevar hasta una tarjeta de 256 GB.
¿Qué se necesita para obtener la garrapata pila en funcionamiento en un pino-64? Como era de esperar, el tiempo para impresionante ™ es realmente corto! Una vez que tenga su caja de pino-64 en funcionamiento - se sugiere emplear la imagen Xenial ya que es la imagen ‘oficial’ Pino-64 y es Ubuntu, así que es muy fácil con InfluxDB. No se olvide de ejecutar
apt-get upgrade
Tan pronto como lo tenga instalado y en funcionamiento para asegurarse de que tienen todo al día.
A continuación, añadir los repositorios de afluencia a apt-get:
curl -sL https://repos.influxdata.com/influxdb.key | apt-key add -
source /etc/lsb-release
echo "deb https://repos.influxdata.com/${DISTRIB_ID,,} ${DISTRIB_CODENAME} stable" | tee -a /etc/apt/sources.list
Es probable que tenga que ejecutar aquellos con sudo, pero engañar y ejecutar ‘fiesta sudo’ para comenzar, y entonces estoy listo.
A continuación, tendrá que añadir un paquete que falta - y necesario - con el fin de acceder a los repositorios InfluxData:
apt-get install apt-transport-https
Entonces es sólo una cuestión de
apt-get install influxdb chronograf telegraf kapacitor
y ya está listo para ir!
Pruebas de carga del dispositivo
Decidí que podría ser una buena idea para poner una carga en este pequeño dispositivo sólo para ver lo que era capaz de manejar, lo que he descargado ‘afluencia de estrés’ de GitHub y corrió contra este dispositivo.
Using batch size of 10000 line(s)
Spreading writes across 100000 series
Throttling output to ~200000 points/sec
Using 20 concurrent writer(s)
Running until ~18446744073709551615 points sent or until ~2562047h47m16.854775807s has elapsed
Wow … eso es 200.000 puntos por segundo! Eso debería poner un poco de estrés serio en mi pequeño pino-64! Y resulta que se hizo una especie de:
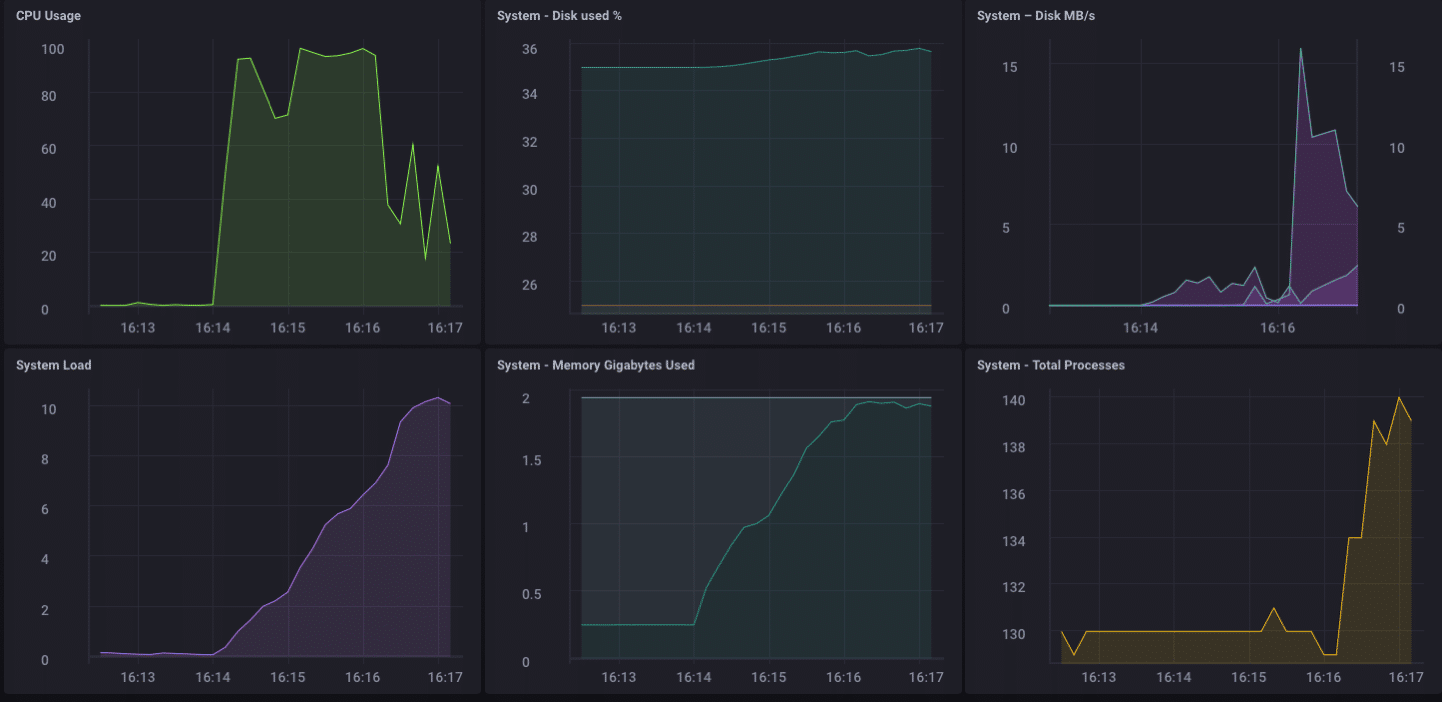
Como se puede ver, es bastante rápidamente superó a cabo el 2 GB de memoria, y vinculado a la CPU al 100%. Sino como un dispositivo de puerta de enlace, es poco probable que, en la vida real, para ver una carga de este tipo. Creo que, en términos de uso de la vida real como una puerta de entrada, estaría bien dentro de mi rango si sólo estaban recogiendo desde unas pocas docenas a tal vez un centenar de sensores.
Analítica local
Como se puede ver desde el panel superior, que pueda hacer fácilmente algunos análisis locales sobre el pino-64. Cuenta con una interfaz HDMI a bordo, y una GPU completo, por lo que permite el acceso local al tablero de instrumentos para el control es muy simple. Pero como he dicho antes, sería mucho más útil si el dispositivo es capaz de hacer más que eso. Es poco probable que, en el mundo real, usted va a recoger todos sus datos en un dispositivo de puerta de enlace y hacer todas sus analíticas, etc. allí. Eso no es lo Terminales / hubs son para. * Algunos de análisis locales *, alertas, etc. serían buenos - mover parte del procesamiento hacia el borde cuando se puede - pero todavía desea reenviar los datos en fases anteriores.
Downsampling los Datos
Es bastante fácil de utilizar simplemente un dispositivo de puerta de enlace para reenviar todos ** ** sus datos en sentido ascendente, pero si usted está tratando con problemas de conectividad de la red, y que está tratando de ahorrar dinero o ancho de banda, o ambos, usted va a querer hacer algunos datos de disminución de resolución antes de reenviar los datos. Afortunadamente esto también es muy fácil de hacer! Un dispositivo de puerta de enlace que puede hacer la analítica locales, manejar algunos de alerta local, y también puede reducir la resolución de los datos antes de pasarlo aguas arriba es enormemente útil en la IO. También es bastante fácil de hacer!
En primer lugar, vamos a configurar nuestro dispositivo de puerta de enlace para poder enviar datos en sentido ascendente a otra instancia de InfluxDB. Hay varias maneras de hacer esto, pero ya que vamos a estar haciendo algunos datos de disminución de resolución a través de Kapacitor, lo haremos a través del archivo kapacitor.conf. El archivo kapacitor.conf ya tiene una sección con una entrada [[influxdb]] para ’localhost’ por lo que sólo tenemos que añadir una nueva sección [[influxdb]] para la instancia aguas arriba:
[[influxdb]]
enabled = true
name = "mycluster"
default = false
urls = ["http://192.168.1.121:8086"]
username = ""
password = ""
ssl-ca = ""
ssl-cert = ""
ssl-key = ""
insecure-skip-verify = false
timeout = "0s"
disable-subscriptions = false
subscription-protocol = "http"
subscription-mode = "cluster"
kapacitor-hostname = ""
http-port = 0
udp-bind = ""
udp-buffer = 1000
udp-read-buffer = 0
startup-timeout = "5m0s"
subscriptions-sync-interval = "1m0s"
[influxdb.excluded-subscriptions]
_kapacitor = ["autogen"]
Que resuelve parte del problema. Ahora necesitamos realmente disminuir la resolución de los datos, y lo enviamos en. Desde que estoy usando Chronograf v1.3.10, tengo un editor incorporado TICKscript, así que voy a ir a la ‘Alerta’ Tab en Chronograf, y crear un nuevo script TICK y seleccione la base de datos telegraf.autoget como mi fuente :
No estoy realmente la recogida de datos de los sensores en este dispositivo todavía, así que voy a utilizar el uso de la CPU como mis datos, y voy a disminuir la resolución que en mi TICKScript. He escrito un TICKScript muy básica para disminuir la resolución de mis datos de la CPU y la enviará aguas arriba:
stream
|from()
.database('telegraf')
.measurement('cpu')
.groupBy(*)
|where(lambda: isPresent("usage_system"))
|window()
.period(1m)
.every(1m)
.align()
|mean('usage_system')
.as('mean_usage_system')
|influxDBOut()
.cluster('mycluster')
.create()
.database('downsample')
.retentionPolicy('autogen')
.measurement('mean_cpu_idle')
.precision('s')
Ese guión simplemente toma el campo usage_system de la medición de la CPU cada minuto, calcula la media, y luego escribe que el valor aguas arriba de mi ejemplo InfluxDB aguas arriba. En el dispositivo de puerta de enlace, los datos de la CPU es el siguiente:
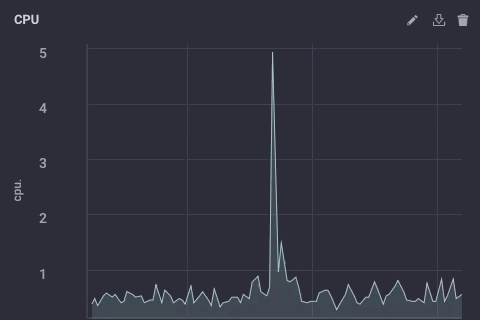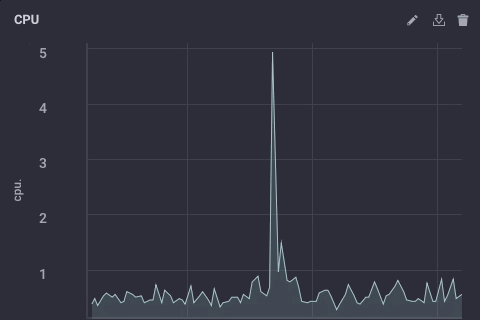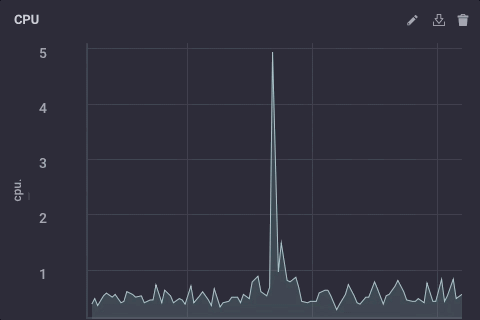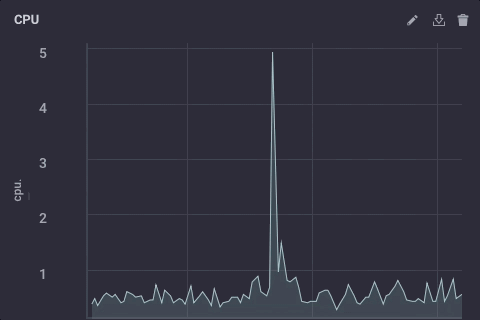
Los datos submuestreadas en mis ejemplo miradas originales de esta forma:
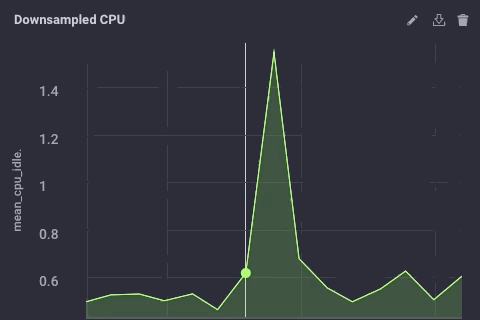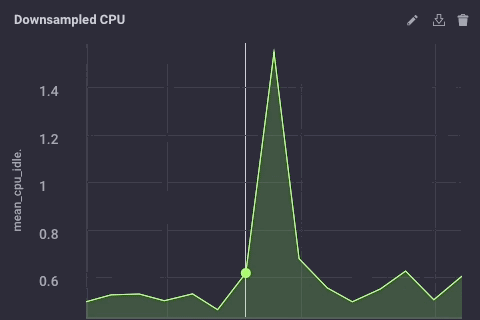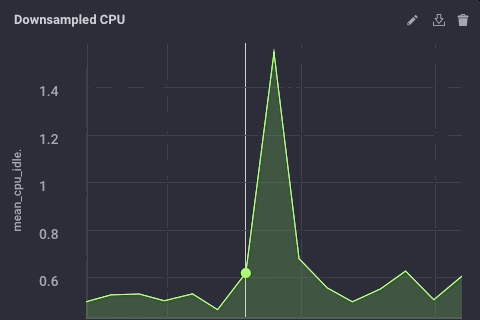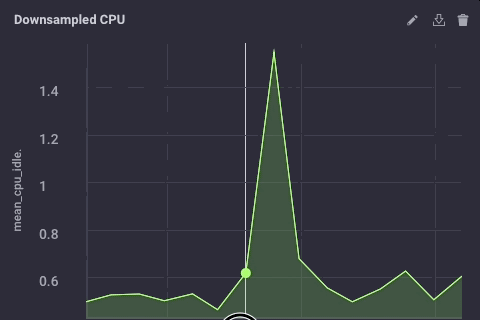
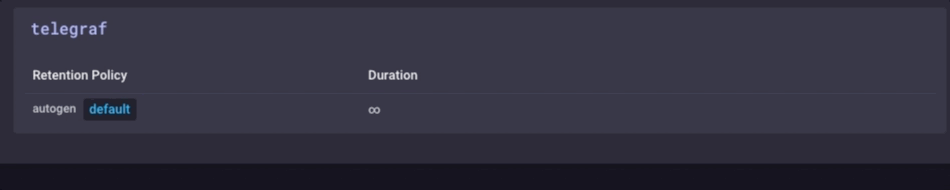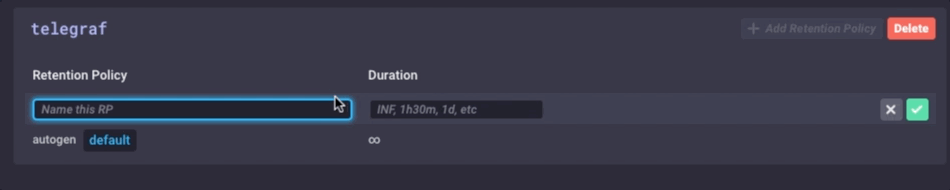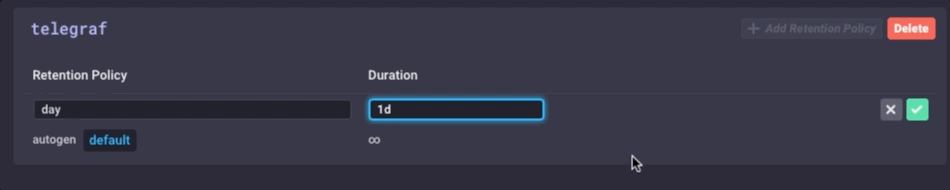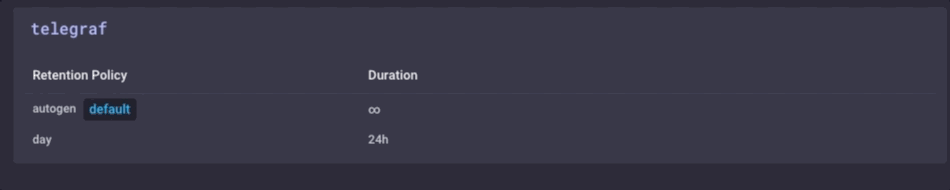
Es la misma los datos, simplemente mucho menos granular. Por último, voy a ir a configurar la política de retención de datos en el dispositivo de puerta de enlace a ser sólo 1 día, así que no llenar el dispositivo pero todavía puedo mantener un poco de la historia local:
Ahora tengo un dispositivo IO puerta de enlace que puede recoger datos de los sensores locales, presentar algunos análisis a un usuario local, hacer algunas alertas locales (una vez he creado algunas alertas kapacitor), y después de disminuir la resolución de los datos locales y enviarlo aguas arriba para mi empresa InfluxDB ejemplo, para su posterior análisis y procesamiento. Puedo tener los datos altamente granulares milisegundos disponibles en el dispositivo de puerta de enlace y los datos menos granulares de 1 minuto en mi dispositivo aguas arriba que me permite todavía tengo idea de los sensores locales sin tener que pagar los costos de ancho de banda para enviar todos los datos río arriba.
También puedo utilizar este método para cadena aún más el almacenamiento de datos mediante el almacenamiento de los datos de 1 minuto en una instancia InfluxDB regional, y expedición de datos-downsampled más adelante a una instancia InfluxDB donde puedo agregar mis datos de los sensores de a través de toda mi empresa.
I ** ** podría simplemente enviar todos los datos arriba en la cadena de mi última agregador de datos de la empresa, pero si estoy agregación de decenas de miles de sensores y sus datos, los costes de almacenamiento y ancho de banda puede empezar a pesar más que la utilidad de la altamente naturaleza granular de los datos.
Conclusión
Me repetir esto tantas veces voy a tener que tener tatuado en la frente, pero voy a decirlo una vez más: la IO Data es realmente sólo es útil si es oportuna, precisa y accionable *** **. * El mayor de sus datos es, cuanto menos procesable se vuelve. Cuanto menos es procesable, menos detalle que necesita. Disminución de la resolución de sus datos, y el establecimiento de políticas de retención de datos cada vez más largos a medida que avanza, se puede asegurar que sus datos altamente inmediata tiene la especificidad de ser altamente procesable y altamente precisa, preservando al mismo tiempo las tendencias a largo plazo en sus datos para el análisis de tendencias a más largo plazo.