
David G. Simmons
jueves, 25 de junio de 2020
¿Qué sucede cuando usted pone su base de datos SQL en Internet
Y después de que lo fijamos a Hacker News.
Si escuchas, bueno, casi cualquier persona racional, que le dirá en términos muy claros que la última cosa que quiero hacer es poner su base de datos SQL en el Internet. E incluso si usted es lo suficientemente loco como para hacer eso, que sin duda nunca jamás volvería publicar la dirección a la que en un lugar como Hacker News. No, a menos que fueras un masoquista de todos modos.
Lo hicimos, sin embargo, y no estamos ni siquiera un poco mal por ello.
La idea
QuestDB ha construido lo que creemos que es el más rápido de base de datos SQL Open Source en la existencia. Realmente hacemos. Y estamos muy orgullosos de ella, de hecho. Tanto es así que hemos querido dar a cualquier persona que quería la oportunidad la oportunidad de llevarlo a dar una vuelta. Con datos reales. Hacer consultas reales. Casi cualquier persona puede reunir una demo que funciona muy bien bajo las condiciones ideales, con todos los parámetros estrictamente controlados.
¿Pero qué sucede si rienda suelta a las hordas en él? ¿Qué ocurre si se deja a nadie consultas de ejecución en contra de ella? Bueno, podemos decir que, ahora.
Lo que es
En primer lugar, se trata de una base de datos de series de tiempo basado en SQL, construido desde cero para el rendimiento. Está construido para almacenar y consulta de grandes cantidades de datos muy rápidamente.
Hemos desplegado en un servidor de AWS c5.metal en el centro de datos de Londres, Reino Unido (lo siento todo lo que los norteamericanos, hay un poco de una función de latencia debido a las leyes de la física). Se configura con 196GB de RAM, pero sólo estaban usando 40GB al uso máximo. La instancia de c5.metal proporciona 2 CPUs 24-núcleo (48 núcleos), pero sólo se utiliza uno de ellos (24 núcleos) en 23 hilos. Realmente no estábamos usando cualquier lugar * * cerca a todo el potencial de esta instancia AWS. Que no aparecían importar en absoluto.
Los datos se almacenan en un volumen AWS EBS que proporciona acceso SSD a los datos. No todo en la memoria.
Los datos son los datos meteorológicos asociados toda NYC Taxi de base de datos más. Que asciende a 1,6 mil millones de registros, con un peso de aproximadamente 350 GB de datos. Eso es mucho. Y es demasiado como para almacenar en memoria. Es demasiado caché.
Hemos proporcionado algunas consultas se puede hacer clic para que la gente comenzó a (ninguno de los resultados se almacenan en caché o precalculados) pero que en esencia no restringir los tipos de consultas que los usuarios podían correr. Que queríamos ver, y permitir a los usuarios ver, lo bien que lo realiza en consulta del tiraron en ella.
No fue decepcionante!
El Hacker News Publica
Hace unas semanas, que escribió acerca de cómo se implementó SIMD instrucciones para agregar mil millones de filas en milisegundos [1] gracias en gran parte a la biblioteca VCL de Agner Fog [2]. Aunque el alcance inicial estaba limitado a los agregados de toda la tabla en un valor escalar único, este era un primer paso hacia resultados en agregaciones más complejas muy prometedor. Con la última versión de QuestDB, estamos extendiendo este nivel de rendimiento a agregaciones basados en claves.
Para ello, hemos implementado tabla de dispersión rápida de Google también conocido como “Swisstable” [3] que se puede encontrar en la biblioteca de Abseil [4]. Con toda modestia, también encontramos la habitación para acelerar un poco para nuestro caso de uso. Nuestra versión de Swisstable es apodado “rosti”, después de que el plato tradicional suiza [5]. También hubo una serie de mejoras gracias a las técnicas sugeridas por la comunidad como de captación previa (que curiosamente resultó tener ningún efecto en el código propio mapa) [6]. Además de C ++, utilizamos nuestro propio sistema de cola escrito en Java para paralelizar la ejecución [7].
Los resultados son notables: la latencia de milisegundos en agregaciones con llave ese lapso de más de mil millones de filas.
Pensamos que podría ser una buena ocasión para mostrar nuestro progreso al hacer esta última versión disponible para probar en línea con un conjunto de datos pre-cargado. Se ejecuta en una instancia AWS utilizando 23 hilos. Los datos se almacenan en el disco e incluye un conjunto de datos 1.6billion fila NYC taxi, de 10 años de datos meteorológicos con alrededor de 30 minutos a la resolución y los precios del gas semanales durante la última década. La instancia se encuentra en Londres, para que la gente fuera de Europa puede experimentar diferentes latencias de red. El tiempo del lado del servidor se reporta como “Ejecutar”.
Proporcionamos consultas de ejemplo para empezar, pero se le anima a modificarlos. Sin embargo, por favor tenga en cuenta que no todos los tipos de consulta es rápido todavía. Algunos todavía están funcionando bajo un viejo modelo de un solo subproceso. Si encuentra uno de estos, usted sabrá: tardará minutos en lugar de milisegundos. Pero hay que tener con nosotros, esto es sólo una cuestión de tiempo antes de hacer estos instantánea también. A continuación en nuestros punto de mira es agregaciones tiempo de cubo utilizando la muestra por cláusula.
Si está interesado en probar la forma en que lo hicimos, nuestro código está disponible de código abierto [8]. Esperamos con interés recibir sus comentarios sobre nuestro trabajo hasta el momento. Aún mejor, nos gustaría escuchar más ideas para mejorar aún más el rendimiento. Incluso después de décadas en la computación de alto rendimiento, todavía estamos aprendiendo algo nuevo cada día.
[1]https://questdb.io/blog/2020/04/02/using-simd-to-aggregate-b?ref=davidgsiot …
[2]https://www.agner.org/optimize/vectorclass.pdf
[3]https://www.youtube.com/watch?v=ncHmEUmJZf4
[4]https://github.com/abseil/abseil-cpp
[5]https://github.com/questdb/questdb/blob/master/core/src/main …
[6]https://github.com/questdb/questdb/blob/master/core/src/main …
[7]https://questdb.io/blog/2020/03/15/interthread?ref=davidgsiot
Y luego nos envió el enlace a la base de datos activa.
Y se echó hacia atrás.
Y vimos el tráfico entrante.
Y trató de no entrar en pánico.
Qué pasó
En primer lugar, hicimos la primera página de Hacker News. Entonces nos quedamos allí. Por horas*.
Vimos una gran cantidad de tráfico. Me refiero a una gran cantidad de tráfico * *. En algún lugar más de 20.000 direcciones IP únicas.
Excluyendo simples consultas show , vimos 17.128 consultas SQL con 2.485 errores de sintaxis en las consultas. Nos envió casi 40 GB de datos en respuesta a las consultas. Los tiempos de respuesta fueron fenomenal. respuestas sub-segundo a casi todas las consultas.
Alguien en los comentarios HN sugirió que las tiendas de columna son malos en une, lo que llevó a alguien que entra y tratando de unirse a la tabla consigo misma. Por lo general, esto sería un asombrosamente mala decisión.
El resultado fue … no es lo que esperaban:
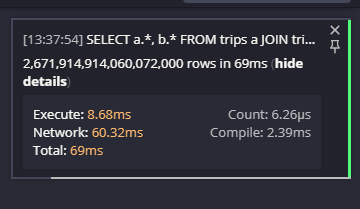
Sí, eso es 2,671,914,914,060,072,000 filas. En 69ms (incluyendo el tiempo de transferencia de la red). Eso es un montón de resultados en un lapso muy corto de tiempo. Definitivamente no es lo que esperaban.
Vimos sólo un par de malos actores probar algo lindo:
2020-06-23T20:59:02.958813Z I i.q.c.h.p.JsonQueryProcessorState [8536] exec [q='drop table trips']
2020-06-24T02:56:55.782072Z I i.q.c.h.p.JsonQueryProcessorState [6318] exec [q='drop *']
Pero los que no ha funcionado. Podemos estar loco, pero no somos ingenuos.
Lo que hemos aprendido
Resulta que cuando se hace algo como esto, se aprende mucho. Se aprende acerca de sus puntos fuertes y sus puntos débiles. Y uno aprende acerca de lo que los usuarios quieren hacer con su producto, así como lo que van a hacer para tratar de romperlo.
Uniéndose a la tabla consigo misma fue una de esas lecciones. Pero también vimos que mucha gente utiliza una cláusula WHERE, lo que provocó resultados bastante lentos. No nos sorprendió en su totalidad por este resultado, ya que somos conscientes de que no hemos hecho las optimizaciones en ese camino para obtener los resultados rápidos que queremos. Pero fue una gran penetración en la frecuencia con que se utiliza, y cómo las personas lo utilizan.
Vimos un número de personas que utilizan el grupo BY cláusula así, y luego se sorprenda de que no funcionó. Probablemente deberíamos haber advertido a la gente acerca de eso. En pocas palabras, grupo BY se infiere de forma automática, por lo que no es necesario. Pero ya que no está implementado en absoluto, que provoca un error. Así que estamos buscando la manera de manejar eso.
Estamos tomando todas estas lecciones, y hacer planes para tratar todo lo que vimos en las próximas versiones.
Conclusiones
Parece que la gran mayoría de las personas que probaron la demo quedamos muy impresionados con él. La velocidad es realmente impresionante.
Éstos son sólo algunos de los comentarios que recibimos en el hilo:
He abusado LEFT JOIN para crear una consulta que produce 224,964,999,650,251 filas. Sólo 3.68ms tiempo de ejecución, ahora que es impresionante!
Muy fresco. Principales apoyos para poner esto por ahí y aceptar consultas arbitrarias.
Muy impresionante, creo que la construcción de su propia base de datos (performant) desde cero es una de las más impresionantes obras de ingeniería de software.
Muy fresco e impresionante !! Es la total compatibilidad de alambre PostreSQL en la hoja de ruta? Yo al igual que la compatibilidad postgres :)
(Sí, Wire Protocol completa PostgreSQL está en la hoja de ruta!)
Exorbitante, no sabía nada de questDB. El botón de retroceso parece roto en el cromo móvil
Sí, la demo hizo romper el botón Atrás de su navegador. Hay una razón real para eso, pero es cierto, por ahora. Definitivamente estamos frente a ese uno de inmediato.
Inténtalo tú mismo
¿Quieres hacerlo por uno mismo? Usted ha leído hasta aquí, que realmente debería! tengo quehttp://try.questdb.io:9000/ para darle una turbina.
Nos encantaría que te unas a nosotros en nuestro Slack Community Channel, nos dan una), nos dan una Estrellas en GitHub, y), y Descargar y tratar de usted mismo!