
David G. Simmons
jueves, 16 de abril de 2020
Este material es rápido!
He hecho un montón de proyectos que utilizan InfluxDB en los últimos años (bueno, yo trabajo allí después de todo) así que tal vez he desarrollado un poco de un sesgo, o un punto ciego. Si sígame en twitter, entonces es posible que me ha visto a publicar algunos videos rápidos de un proyecto que estaba trabajando para la visualización de COVID-19 datos sobre un mapa.
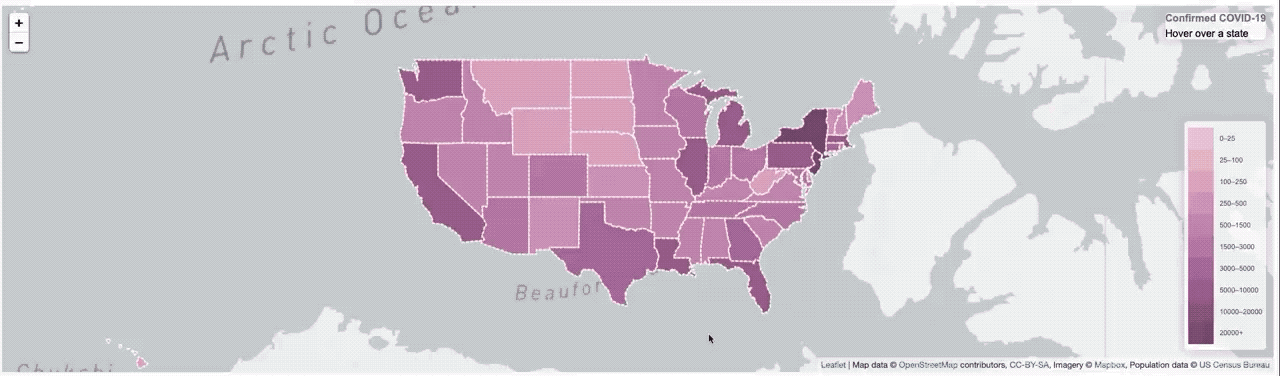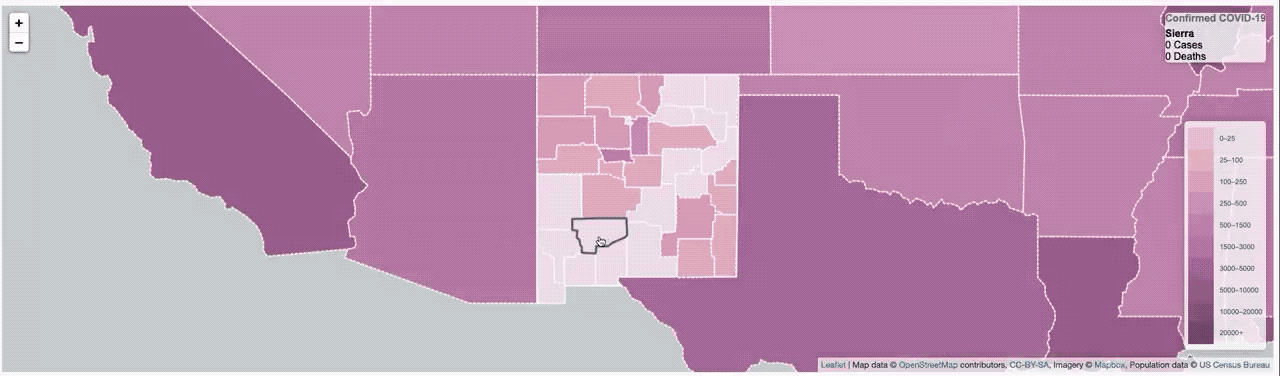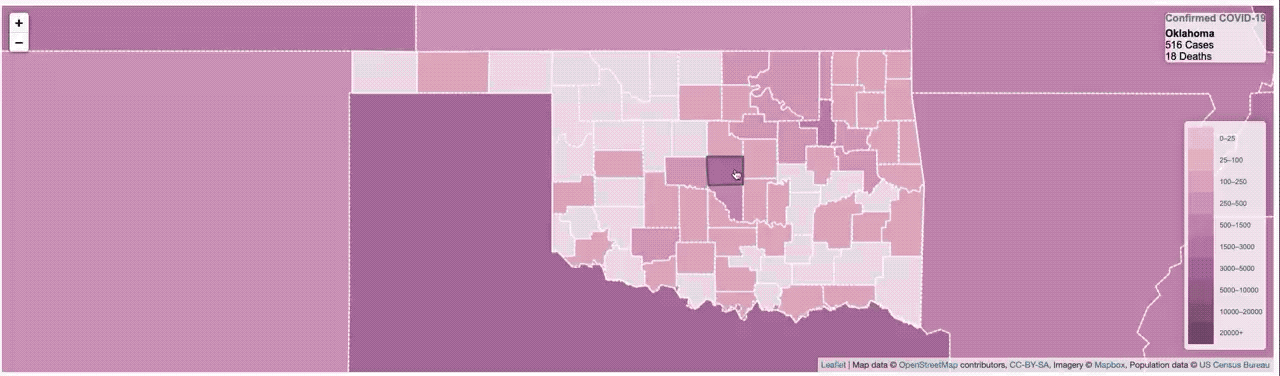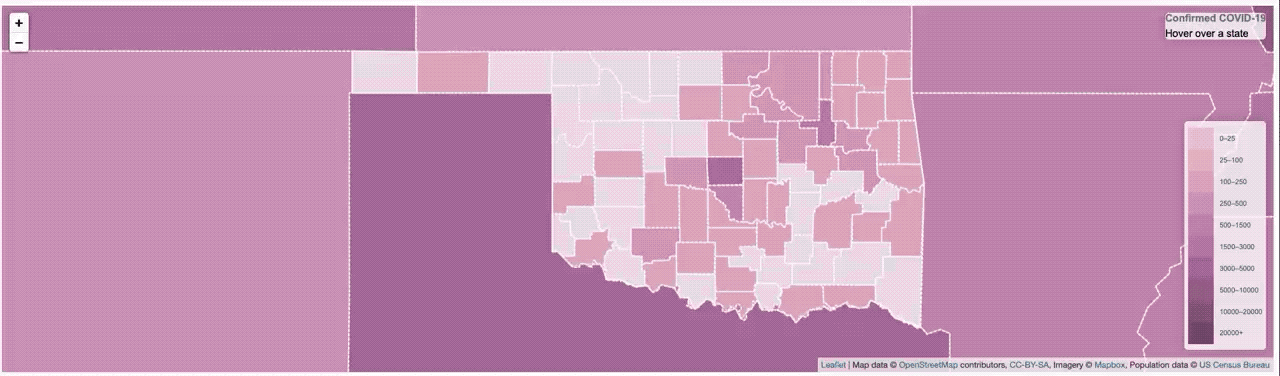 It worked, but it was pretty slow. So much so that I had to put a ’loading’ overlay on it so you knew it was still actually doing something while it was querying the data from the database. I actually sort of thought it was pretty fast, until I started trying to load data from all of Asia, or all of Europe, where that was a lot of data and the query got complicated.
It worked, but it was pretty slow. So much so that I had to put a ’loading’ overlay on it so you knew it was still actually doing something while it was querying the data from the database. I actually sort of thought it was pretty fast, until I started trying to load data from all of Asia, or all of Europe, where that was a lot of data and the query got complicated.
Pero, puesto que ya no funcionan en InfluxData que decidió diversificarse un poco y probar otras soluciones. Es decir, cuál es el daño, ¿verdad? He encontrado este pequeño inicio haciendo una base de datos basada en SQL Time Series llamada QuestDB, así que pensé que le daría una oportunidad. Muy pequeño (básicamente integrable) y todo lo escrito en Java (hey, yo solía hacer de Java! Comenzado en 1995, de hecho!) Así que demonios.
Francamente, estoy aturdido. El rendimiento de esta cosa es alucinante. Basta con mirar a esto:
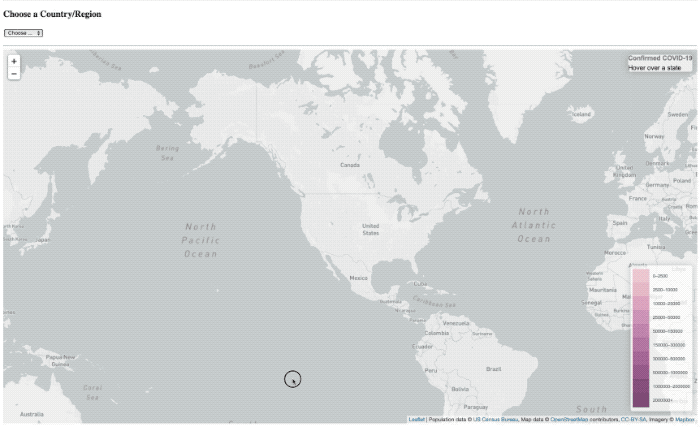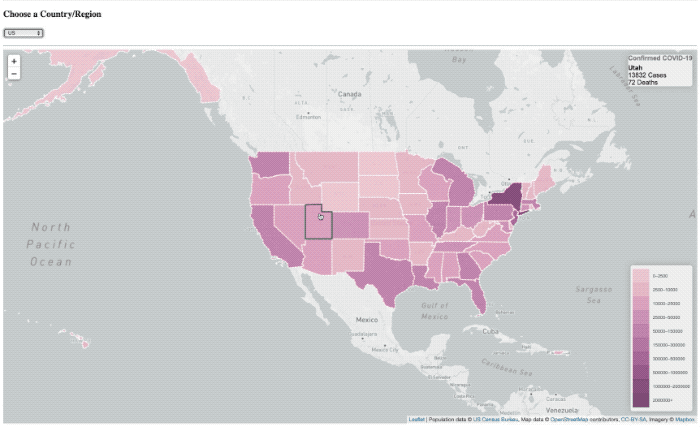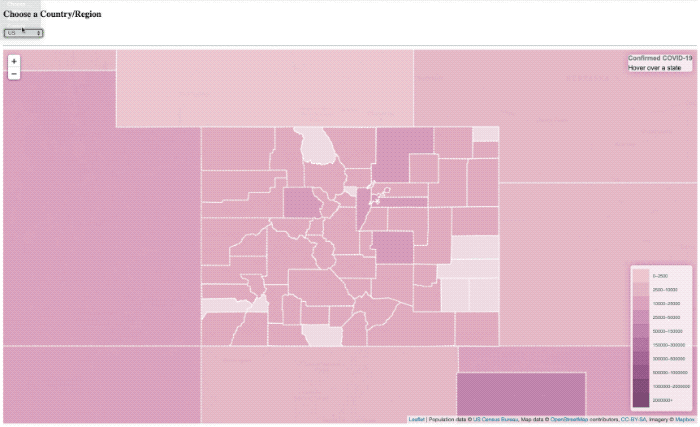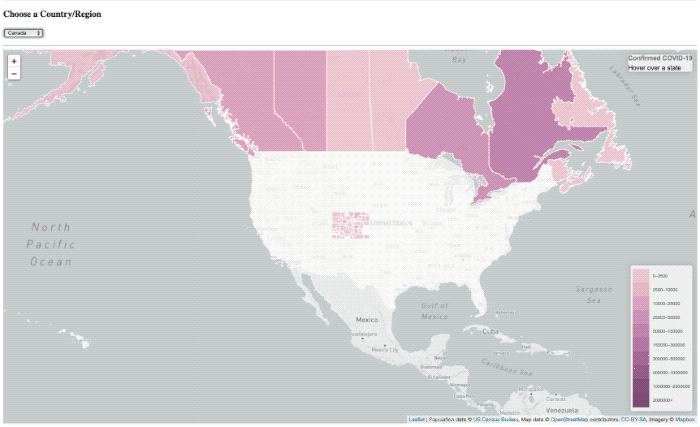
La superposición de ‘carga’ sigue ahí, sólo básicamente no tiene el tiempo para presentarse nunca más.
Además, el lenguaje de consulta SQL es …. Demonios, incluso *** *** Yo sé SQL! Tengo que quitarle el polvo un poco, ya que han pasado años desde que escribí ninguna, pero es como andar en bicicleta, en su mayoría.
Usted está probablemente va a preguntarme, desde que hice una cosa muy importante de ella antes, “sí, pero ¿cuánto tiempo se tarda en configurarlo?” Te lo diré: 30 segundos. Lo descargué y corrió el guión startquestdb.sh… y su puesta en marcha. Por supuesto, no tenía los datos, así que tuve que cargar todo. Ok, así que ¿cuánto tiempo tardará? Y lo difícil era? Bueno, ummm …
Alteré mi programa Go que había metamorfoseado previamente todos los datos de la Hopkins John COVID-19 a partir de sus archivos .csv a las corrientes de archivos de protocolo de línea, por lo que pasé unos minutos alterar ** ** que para que todo lo que la producción en un único y unificado , archivo .csv normalizado (JHU cambia el formato de sus archivos csv muy a menudo, así que tengo que seguir adaptándose). Una vez que tuve de eso, sólo arrastrar y lo dejó caer en la interfaz QuestDB:
En caso de que se ha perdido, era de 77.000 filas importadas en 0,2 segundos.

Ah, y luego hice clic en el icono de ‘vista’ y … 77.000 filas leídas en 0.016 segundos. Y ese número es ** ** no es un error tipográfico. de punto cero-cero-uno-seis segundos. Por supuesto, las filas no son tan amplia, pero aún así, eso es lo profano rápido.
Así que ahora tengo un nuevo juguete para jugar, y voy a ver qué más puedo hacer con él lo que es divertido, y probablemente más relacionadas con la IO.
Manténganse al tanto.