
David G. Simmons
jueves, 5 de diciembre de 2019
Datos de la IO de otras fuentes de MySQL
Si ha implementado una solución de la IO, que ha tenido que decidir dónde y cómo, para almacenar todos sus datos. Al menos desde mi punto de vista, la mejor y más fácil de lugar para almacenar los datos de los sensores es, por supuesto, InfluxDB. Mi diciendo que no puede venir como una sorpresa para usted. Pero ¿qué pasa con los otros datos * * que necesita para tienda? * Los datos sobre los sensores *? Cosas como el fabricante del sensor, la fecha en que fue puesto en servicio, el ID de cliente, qué tipo de plataforma que se está ejecutando. Ya sabes, todos los metadatos del sensor.
Una solución, por supuesto, es simplemente agregar todas esas cosas como etiquetas a los datos de los sensores en InfluxDB y seguir sobre su día. Pero, ¿realmente * * desea almacenar todos sus datos de sensores con cada punto de datos? Hay muchas cosas que parecen como una buena idea en ese momento, pero luego recaen rápidamente en una idea terrible cuando la realidad éxitos. Dado que la mayoría de estos metadatos no cambia a menudo, y también puede estar asociada con la información del cliente, el mejor lugar para ello es muy probable que en un RDBMS tradicional. Lo más probable es que ya tiene * * un RDBMS con los datos del cliente en el mismo, por lo que ¿por qué no continuar aprovechando que la inversión? Como he dicho en repetidas ocasiones, esto es ** ** No es el mejor lugar para sus datos del sensor. Así que ahora que tienes los datos de la IO en dos bases de datos diferentes. ¿Cómo se accede a él y lo combine con un lugar donde se puede ver todo?
Flux es la respuesta
Dime que viste que viene. Tenías que haber visto venir. Ok, para ser justos, es posible que tenga porque, después de todo, ¿cómo se va a conseguir sus datos basadas en SQL a través de Flujo? Esa es la belleza de Flujo: es extensible! Así que ahora tenemos una extensión que le permite leer los datos desde cualquiera de MySQL, PostgreSQL o MariaDB a través de Flujo. Cuando supe que este conector SQL estaba listo para ir, sólo tenía que probarlo. Te voy a mostrar lo que he construido, y cómo.
Construir una base de datos de clientes
El primero que hay que hacer era construir una base de datos MySQL con un poco de información al cliente. He creado una nueva base de datos llamada IoTMeta en el que pongo una tabla con algunos metadatos del sensor. También he añadido otra tabla con la información del cliente acerca de esos sensores.

cuadros básicos bonitos, de verdad. El campo Me Sensor_ID rellena con datos correspondientes a la etiqueta Sensor_id en mi ejemplo InfluxDB. Apuesto a que puede ver a dónde voy con esto ya. He añadido un montón de datos:

Así que ahora mi base de datos de metadatos sensor tiene alguna información acerca de cada sensor Estoy corriendo aquí, así como algunos datos de los clientes ’’ sobre quién es dueño de los sensores. Ahora es el momento de tirar de todo esto en algo útil.
Consulta de los datos con Flux
En primer lugar, he construido una consulta en Flujo de conseguir algunos de mis datos de los sensores, pero no estaba realmente interesado en la propia datos del sensor. Yo estaba buscando un valor de etiqueta de identificación: Sensor_id. Esta consulta se verá un poco extraño, pero va a tener sentido en el final, lo prometo.
temperature = from(bucket: "telegraf")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r._measurement == "temperature" and (r._field == "temp_c"))
|> last()
|> map(fn: (r) => {
return { query: r.Sensor_id }
})
|> tableFind(fn: (key) => true) |> getRecord(idx: 0)
Devuelve una tabla de una fila, y luego se retira la etiqueta Sensor_id, y ahí es donde probablemente estás diciendo“Whaaaat?” Recuerde: Flujo vuelve todo en tablas. Lo que necesito es esencialmente un valor escalar de esa mesa. En este caso, se trata de un valor de cadena para la etiqueta en cuestión. Así es como se hace eso.
A continuación, voy a obtener el nombre de usuario y la contraseña de mi base de datos MySQL, que se almacena convenientemente en el InfluxDB Secretos tienda.
uname = secrets.get(key: "SQL_USER")
pass = secrets.get(key: "SQL_PASSW")
Espera, ¿cómo he llegado esos valores en esta Secretos Almacenar todos modos? Bien, vamos a realizar copias de seguridad de un minuto.
curl -XPATCH http://localhost:9999/api/v2/orgs/<org-id>/secrets -H 'Authorization: Token <token>' -H 'Content-type: application/json' --data '{ "SQL_USER": “<username>" }'
Una cosa a destacar es que se obtiene el <org-id> Fuera de su URL. Es ** ** no el nombre real de su organización en InfluxDB. Entonces haces lo mismo para el secreto SQL_PASSW. Se les puede llamar lo que quieras, de verdad. Ahora usted no tiene que poner su nombre de usuario / contraseña en texto plano en su consulta.
A continuación, voy a utilizar todo eso para construir mi consultas SQL:
sq = sql.from(
driverName: "mysql",
dataSourceName: "${uname}:${pass}@tcp(localhost:3306)/IoTMeta",
query: "SELECT * FROM Sensor_data, Customer_Data WHERE Sensor_data.Sensor_ID = ${"\""+temperature.query+"\" AND Sensor_data.measurement = \"temperature\" AND Sensor_data.CustomerID = Customer_Data.Customer_ID"}" //"SELECT * FROM Sensor_data WHERE Sensor_ID = ${"\""+temperature.query+"\" AND measurement = \"temperature\""}" //q // humidity.query //"SELECT * FROM Sensor_Data WHERE Sensor_ID = \"THPL001\""// humidity.query
)
Verá que estoy usando el valor de mi primera consulta Flux en la consulta SQL. ¡Fresco! Es posible que también aviso de que estoy realizando una join en que la consulta SQL para que pueda obtener datos de ambas tablas * * en la base de datos. ¿Cuan genial es eso? A continuación, voy a dar formato a la tabla resultante de tener sólo las columnas que desea mostrar:
fin = sq
|> map(fn: (r) => ({Sensor_id: r.Sensor_ID, Owner: r._Sensor_owner, Manufacturer: r.Sensor_mfg, MCU_Class: r.MCU_class, MCU_Vendor: r.MCU_vendor, Customer: r.Customer, Address: r.Address, Phone: r.phone}))
ahora tengo una tabla que contiene todos los metadatos acerca de mi sensor, así como todos los datos de contacto del cliente sobre ese sensor. Es hora de un poco de magia:
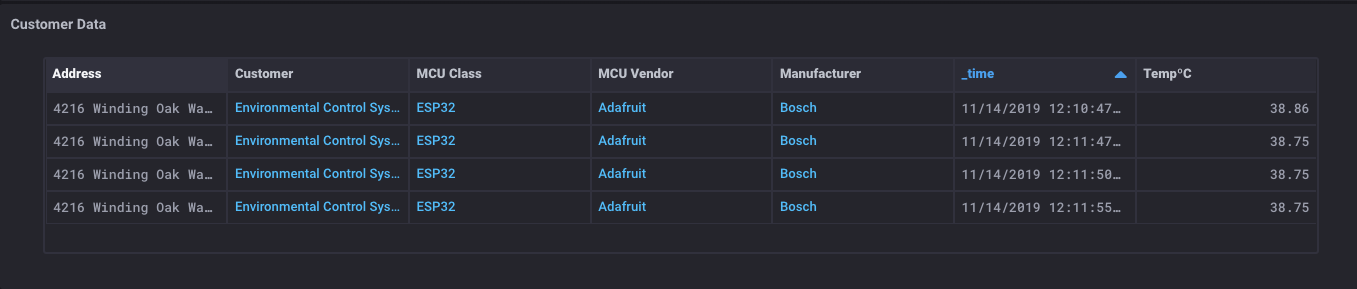
¿Qué es esta hechicería? Tengo una tabla que tiene todos los metadatos sobre el sensor, algunos datos de los clientes, ** y ** las lecturas del sensor también? Sí. Hago. Y aquí está lo realmente mágico: Ya que se puede obtener datos de dos bases de datos SQL * * InfluxDB y cubos, también puede unirse a que los datos en una sola tabla.
He aquí cómo lo hice:
temp = from(bucket: "telegraf")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r._measurement == "temperature" and (r._field == "temp_c"))
me pone una tabla de los datos del sensor. Ya tengo una tabla de los metadatos de SQL, así que …
j1 = join(tables: {temp: temp, fin: fin}, on: ["Sensor_id"] )
|> map(fn: (r) => ({_value: r._value, _time: r._time, Owner: r.Owner, Manufacturer: r.Manufacturer, MCU_Class: r.MCU_Class, MCU_Vendor: r.MCU_Vendor, Customer: r.Customer, Address: r.Address, Phone: r.phone}))
|> yield()
Acabo de unirse a esos dos mesas en un elemento común (el campo Sensor_id) y tengo una tabla que tiene todo en un solo lugar!
Hay varias maneras que usted puede utilizar esta habilidad para combinar datos de diferentes fuentes. Me gustaría saber cómo se llevaría a cabo algo como esto para entender mejor sus implementaciones de sensores.
He hecho todo esto mediante la acumulación de Alpha18 InfluxDB 2.0, que es lo que corro - De hecho, me encargo de construir mi versión de la ‘master’ porque tengo algunas adiciones de fundente que yo uso, pero eso es otro post entero. Para esto, el Alfa construye de OSS InfluxDB 2.0 funcionan bien. Usted debe absolutamente darle una oportunidad!