
David G. Simmons
Montag, 18. Dezember 2017
„Building Ein IoT-Gateway Gerät zur lokalen Alerting und Datendownsampling“
Es gibt alle Arten von Möglichkeiten, um Architekten Ihrer IoT Bereitstellung und was richtig ist für ein Unternehmen wird nicht unbedingt das Richtige für eine andere sein. Je nach Größe und Komplexität des IoT-Projektes kann es sein, natürlich, viele Komponenten. Einer des universellere Architekturen zu Sensorhubs oder Gateway-Geräte, um Daten aus einer Anzahl von Sensorknoten einsetzen und dann nach vorne, dass die Daten an ein Upstream-Datenerfassungssystem für das Unternehmen. Diese Gateway oder Hub-Geräte ermöglichen typischerweise ein Z-Wave-Gerät an das Internet nach Daten-Upload oder an Brücke zwischen Bluetooth-Geräten mit einem WLAN oder einem anderen Netzwerkverbindung zu verbinden.
Darüber hinaus sind die meisten dieser Gateway oder Hub-Geräte neigen ‚stummen‘ Gateways zu sein. Sie tun nichts anderes, als nach vorne Daten an einem vorgeschalteten Sammler. Aber was, wenn der IoT-Gateway könnte ein intelligentes Gerät sein? Was passiert, wenn Sie ** vor lokale Analytik und Datenverarbeitung auf dem Hub-Gerät tun könnten, die Daten ** Senden an? Wäre das nicht nützlich sein!
Aufbau eines Gateway
Ich beschloss, zu bauen (anderes) IoT Smart-Gateway-Gerät an diesem Morgen. Ich habe (Art) baut man vor in Form eines ARTIK-520 läuft InfluxDB. Aber ein ARTIK-520 ist nicht das billigste, was da draußen, und wenn Sie bauen IoT-Geräte, manchmal billiger ist besser. Nicht immer, aber wenn man viele, viele Gateways Gebäude sind, die Sie lieber nicht brechen die Bank auf sie. Ich grub meine) in Form eines ARTIK-520 läuft InfluxDB. Aber ein ARTIK-520 ist nicht das billigste, was da draußen, und wenn Sie bauen IoT-Geräte, manchmal billiger ist besser. Nicht immer, aber wenn man viele, viele Gateways Gebäude sind, die Sie lieber nicht brechen die Bank auf sie. Ich grub meine Pine-64 Box heraus, dass ich vor ein paar Jahren gekauft vor und nach der Arbeit bekam. Warum Pine-64 und nicht Raspberry Pi? Nun, die Pine-64 ist etwa 1/2 der Kosten. Ja, 1/2 der Kosten. Es ist $ 15 statt $ 35, so dass es das ist. Es hat genau die gleichen ARM A53 Quad-Core-Prozessor mit 1,2 GHz - Mine verfügt über 2 GB Speicher, gegenüber dem 1 GB auf einem RPi - und es hat eine leistungsfähigeren GPU, wenn Sie in diese Art der Sache sind. Es kam auch mit eingebautem WiFi, so dass kein Dongle, und ich bekam die Z-Wave-Zusatzkarte, damit ich an Unter GHz IoT-Geräten sprechen kann.
Eines der schönen Dinge über diese Art von Geräten wie IoT Gateways ausgeführt ist, dass Sie nur in Ihrem Speicher durch die Größe der microSD-Karte, die Sie verwenden, beschränkt sind. Ich verwende nur eine 16 GB-Karte, aber die Pine-64 kann auf eine 256 GB-Karte aufzunehmen.
Was braucht es, die Zecke stapeln und läuft auf einem Pine-64 zu bekommen? Es überrascht nicht, die Zeit zu Super ™ ist wirklich kurz! Sobald Sie Ihre Pine-64-Box zum Laufen - Ich schlage vor, mit dem Xenial Bild, wie es das ‚offizielle‘ Pine-64 Bild und es ist Ubuntu, so ist es super einfach mit InfluxDB. Vergessen Sie nicht, laufen
apt-get upgrade
Sobald Sie es haben und läuft sicher, dass Ihr, dass alles auf dem neuesten Stand sind.
Als nächstes fügen Sie die Influx-Repositorys zu apt-get:
curl -sL https://repos.influxdata.com/influxdb.key | apt-key add -
source /etc/lsb-release
echo "deb https://repos.influxdata.com/${DISTRIB_ID,,} ${DISTRIB_CODENAME} stable" | tee -a /etc/apt/sources.list
Sie müssen wahrscheinlich die mit sudo laufen, aber ich betrügen und run ‚sudo bash‘ mit zu beginnen und dann bin ich fertig.
Als Nächstes müssen Sie ein Paket hinzufügen, fehlt - und notwendig -, um den Zugriff auf die InfluxData Repositories:
apt-get install apt-transport-https
Dann ist es nur eine Frage der
apt-get install influxdb chronograf telegraf kapacitor
und Sie sind bereit zu gehen!
Load Testing des Geräts
Ich beschloss, es wäre eine gute Idee zu sein, eine Last auf diesem kleinen Gerät zu setzen, um zu sehen, was es war fähig zur Behandlung, so dass ich heruntergeladen ‚Zustrom-Stress‘ von GitHub und lief es gegen dieses Gerät.
Using batch size of 10000 line(s)
Spreading writes across 100000 series
Throttling output to ~200000 points/sec
Using 20 concurrent writer(s)
Running until ~18446744073709551615 points sent or until ~2562047h47m16.854775807s has elapsed
Wow … das ist 200.000 Punkte pro Sekunde! Das sollte einige ernsthafte Belastung für meinen kleinen Pine-64 setzen! Und es stellt sich heraus, es ist eine Art tat:
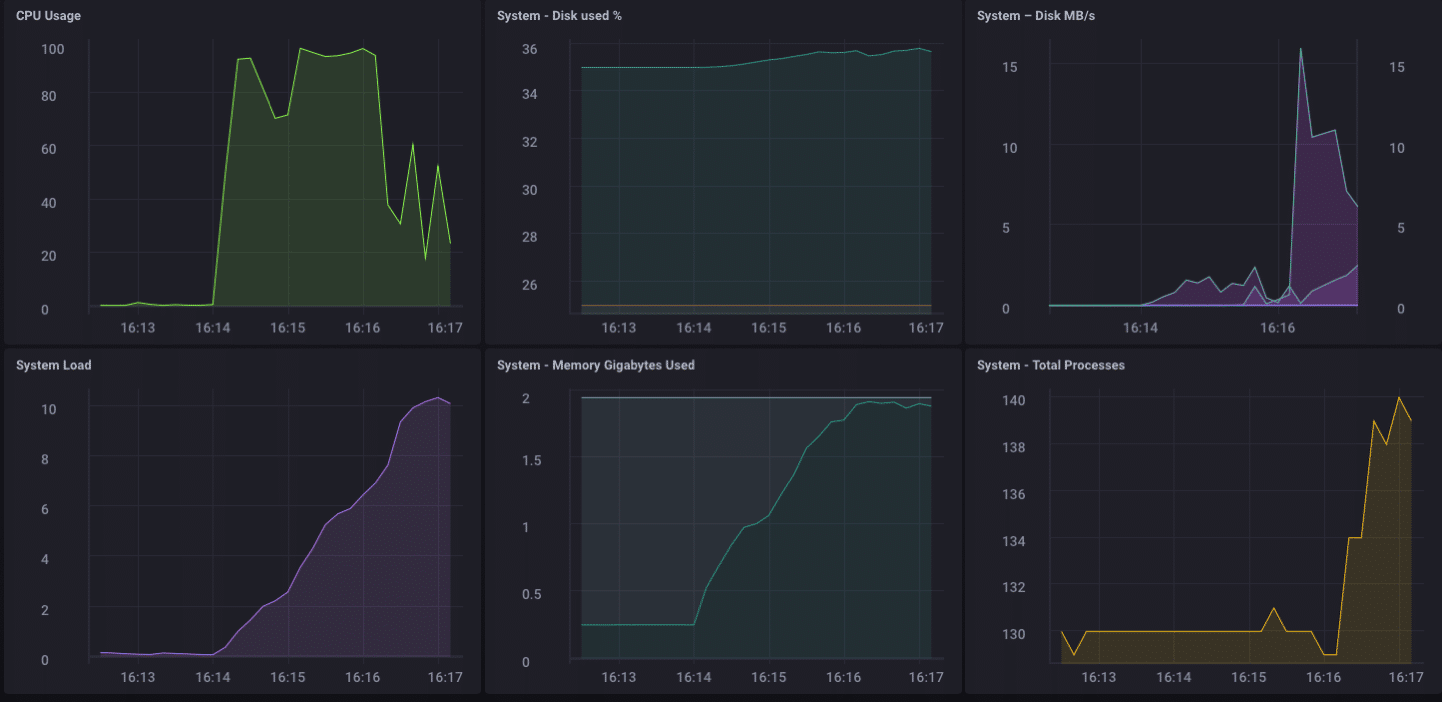
Wie Sie sehen können, ist es gekrönt ziemlich schnell die 2 GB Speicher aus und hängen Sie die CPU auf 100%. Aber als Gateway-Gerät, es ist unwahrscheinlich, im wirklichen Leben, um zu sehen, eine solche Last. Ich denke, in Bezug auf die realen Nutzung als Gateway, würde ich in meinem Bereich gut, wenn ich nur von ein paar Dutzend, vielleicht hundert oder so Sensoren sammeln wurden.
Lokale Analytics
Wie Sie oben im Dashboard sehen kann, kann ich leicht einige lokale Analysen auf der Pine-64 tun. Es verfügt über eine integrierte HDMI-Schnittstelle und eine volle GPU, so lokalen Zugriff auf das Dashboard zur Überwachung erlaubt ist tot einfach. Aber wie ich bereits sagte, wäre es viel sinnvoller sein, wenn das Gerät mehr als das tun könnte. Es ist unwahrscheinlich, dass in der realen Welt, Sie gehen alle Ihre Daten auf einem Gateway-Gerät zu sammeln und zu tun, alle Ihre Analysen usw. gibt. Das ist nicht das, was Gateways / Hub ist für. * Einige * lokale Analysen, Alarmierung, würde usw. gut sein - einen Teil der Verarbeitung aus zum Rand hin bewegen, wenn Sie können - aber Sie wollen noch Upstream-Daten übermitteln.
Downsampling die Daten
Es ist ziemlich einfach, einfach ein Gateway-Gerät ** alle ** Ihre Daten-Upstream, weiterleiten verwenden, aber wenn man es zu tun mit Netzwerkverbindungsproblemen, und Sie versuchen, Geld oder Bandbreite oder beides zu sparen, Sie gehen zu wollen, einige Daten zu tun Abwärtsabtastens, bevor Sie Ihre Daten übermitteln. Zum Glück auch das ist wirklich einfach zu tun! Eine Gateway-Vorrichtung, die lokalen Analytik tun, einige lokale Alarmierungshandhaben, und auch die Daten, die er vor der Übergabe Downsampling kann stromaufwärts ist äußerst nützlich in IoT. Es ist auch ziemlich einfach zu tun!
Lassen Sie uns zunächst unsere Gateway-Gerät Set up der Lage sein, Daten an eine andere Instanz von InfluxDB stromaufwärts zu übermitteln. Es gibt mehrere Möglichkeiten, dies zu tun, aber da werden wir einige Daten zu tun, über Kapacitor Abwärtsabtastens, werden wir es über die kapacitor.conf Datei tun. Die kapacitor.conf Datei hat bereits einen Abschnitt mit einem [[influxdb]] Eintrag für ‚localhost‘, so dass wir gerade einen neuen hinzufügen müssen [[influxdb]] Abschnitt für die Upstream-Instanz:
[[influxdb]]
enabled = true
name = "mycluster"
default = false
urls = ["http://192.168.1.121:8086"]
username = ""
password = ""
ssl-ca = ""
ssl-cert = ""
ssl-key = ""
insecure-skip-verify = false
timeout = "0s"
disable-subscriptions = false
subscription-protocol = "http"
subscription-mode = "cluster"
kapacitor-hostname = ""
http-port = 0
udp-bind = ""
udp-buffer = 1000
udp-read-buffer = 0
startup-timeout = "5m0s"
subscriptions-sync-interval = "1m0s"
[influxdb.excluded-subscriptions]
_kapacitor = ["autogen"]
Das löst einen Teil des Problems. Jetzt müssen wir tatsächlich Downsample die Daten und senden sie an. Da ich Chronograf v1.3.10 bin mit, habe ich einen eingebauten in TICKscript Editor, so dass ich auf die ‚Alerting‘ Tab in Chronograf gehen werde, und ein neues TICK Script erstellen, und wählen Sie die telegraf.autoget Datenbank als meine Quelle :
Ich sammle nicht wirklich Sensordaten auf diesem Gerät noch, so dass ich die CPU-Auslastung als meine Daten verwenden werden, und ich werde es in meinem TICKScript Downsampling. Ich habe eine sehr grundlegende TICKScript geschrieben meine CPU Daten und Downsampling vorwärts es stromaufwärts:
stream
|from()
.database('telegraf')
.measurement('cpu')
.groupBy(*)
|where(lambda: isPresent("usage_system"))
|window()
.period(1m)
.every(1m)
.align()
|mean('usage_system')
.as('mean_usage_system')
|influxDBOut()
.cluster('mycluster')
.create()
.database('downsample')
.retentionPolicy('autogen')
.measurement('mean_cpu_idle')
.precision('s')
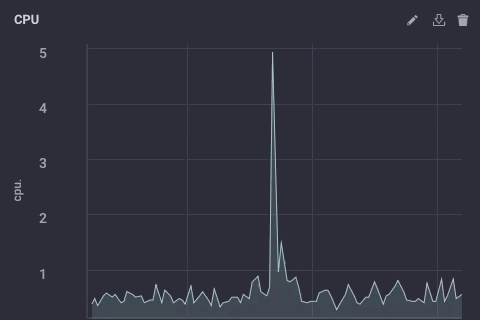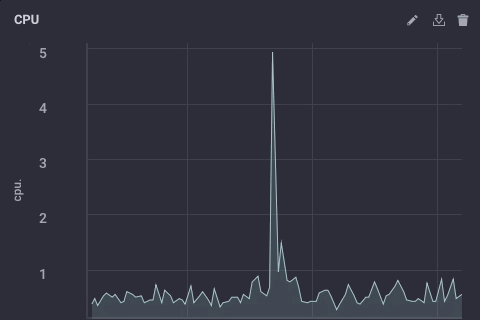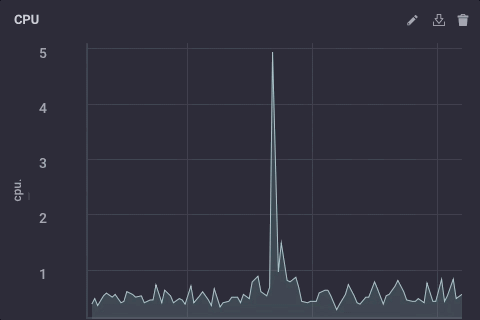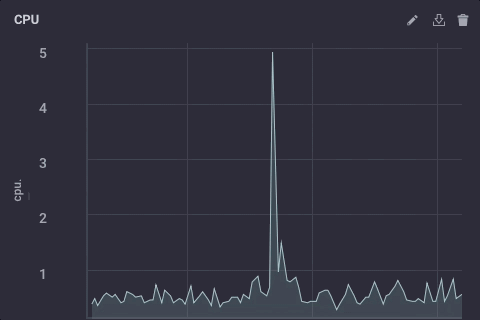
Das Skript nimmt einfach den usage_system Bereich der CPU Messung jede Minute, berechnet den Mittelwert, und dann schreibt diesen Wert vorgeschalteten meine Upstream InfluxDB Instanz. Auf dem Gateway-Gerät sieht die CPU Daten wie folgt aus:
Die abwärts abgetasteten Daten auf meinem Upstream-Instanz sieht wie folgt aus:
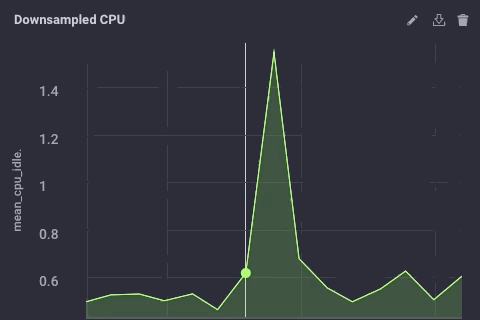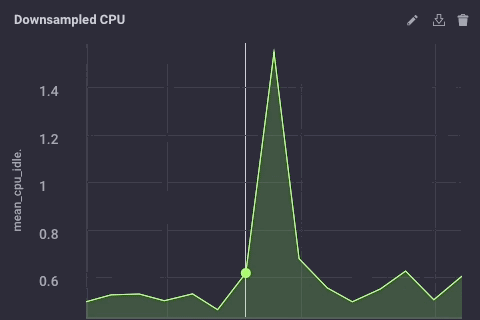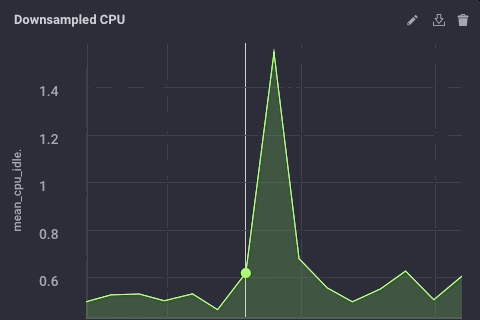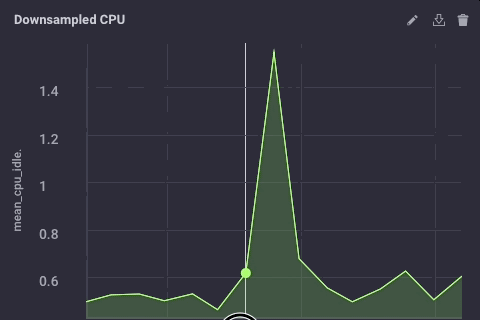
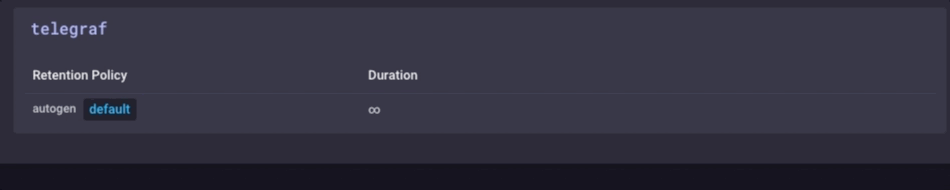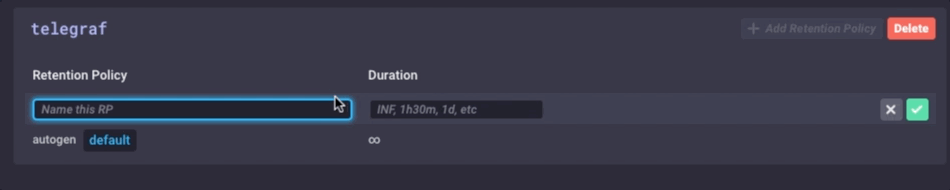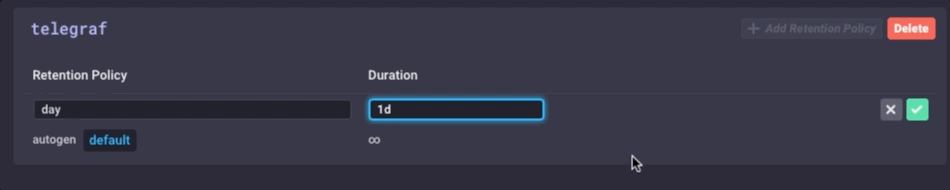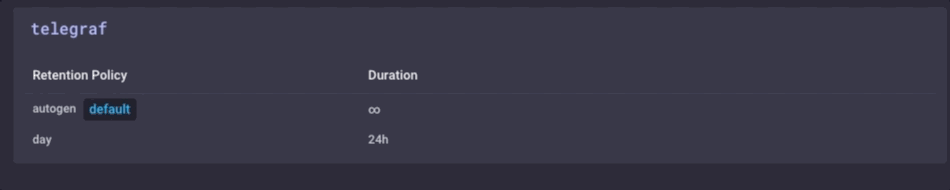
Es ist die gleichen Daten, nur viel weniger körnig. Schließlich werde ich die Datenaufbewahrungsrichtlinien auf meinem Gateway-Gerät festgelegt gehe nur 1 Tag zu sein, so dass ich das Gerät nicht füllen, aber ich kann immer noch ein bisschen Geschichte aufrechtzuerhalten lokal:
Ich habe jetzt ein IoT-Gateway-Gerät, die lokalen Sensordaten sammeln kann, einige Analysen an einem lokalen Benutzer präsentiert, einige lokal Alarmierungs (nachdem ich einige kapacitor-Benachrichtigungen einrichten), und dann Neuberechnung der lokalen Daten und sendet es an mein Unternehmen Upstream InfluxDB Beispiel für die weitere Analyse und Verarbeitung. Ich kann haben die hoch-granulare Millisekunde Daten auf dem Gateway-Gerät, und die weniger körnigen 1-Minuten-Daten auf meinem Upstream-Gerät erlaubt mir noch Einblick haben in die lokalen Sensoren, ohne die Kosten für Bandbreite für Senden alle Daten zu bezahlen Upstream.
Ich kann diese Methode auch zur weiteren Kette des Datenspeicher durch Speicher die 1-Minuten-Daten auf einem regionalen InfluxDB Beispiel, und die Weiterleitung weiter abwärts abgetasteten Daten zu einer InfluxDB Instanz verwenden, wo ich meine Sensordaten über mein gesamtes Unternehmen aggregieren kann.
I ** ** konnte nur alle Daten auf der Kette mein ultimatives Unternehmensdaten Aggregator schicken, aber wenn ich Zehntausende von Sensoren und deren Daten, die Speicher- und Bandbreitenkosten können beginnen zu überwiegen den Nutzen der hoch- aggregieren körnige Natur der Daten.
Fazit
Ich wiederhole dies so oft könnte ich es auf meiner Stirn tätowiert haben müssen, aber ich sage es noch einmal: IoT Daten ist wirklich nur sinnvoll, wenn es an der Zeit ist, präzise und verwertbare *** **. * Je älter Ihre Daten sind, desto weniger verwertbare wird es. Je weniger verwertbare es ist, desto weniger Details, die Sie benötigen. in Ihren Daten für die längerfristige Trendanalyse Abwärtsabtastens Ihre Daten, und wie Sie immer längere Datenaufbewahrungsrichtlinien einstellen, gehen Sie kann sicherstellen, dass Ihre sehr unmittelbaren Daten, die Spezifität hoch umsetzbare zu sein und sehr genau, während die langfristigen Trends zu erhalten.