
David G. Simmons
Donnerstag, 25. Juni 2020
„Was passiert, wenn Sie Ihre SQL-Datenbank im Internet Put“
Und dann konnten wir es zu Hacker News.
Wenn Sie hören, na ja, so ziemlich jeder rational, werden sie Ihnen in aller Deutlichkeit sagen, dass das letzte, was Sie jemals tun wollen, ist Ihre SQL-Datenbank im Internet setzen. Und selbst wenn du bist verrückt genug, um das zu tun, würden Sie sicherlich nie die Adresse, um es an einem Ort wie Hacker News gehen posten. Nicht, wenn Sie sowieso ein Masochist waren.
Wir haben es aber, und wir sind nicht einmal ein wenig leid.
Die Idee
QuestDB gebaut hat, was wir denken, der schnellste Open Source SQL-Datenbank existiert. Wir tun wirklich. Und wir sind ziemlich stolz darauf, in der Tat. So sehr, dass wir jemanden geben wollten, dass die Möglichkeit, es zu wagen es für eine Spritztour wollte. Mit realen Daten. Doing reale Abfragen. Fast jeder kann eine Demo an einem Strang ziehen, dass führt groß unter genau die richtigen Bedingungen, mit allen Parametern streng kontrolliert.
Aber was passiert, wenn man die Horden auf sie entfesseln? Was passiert, wenn Sie jemand laufen Abfragen dagegen lassen? Nun, wir können Ihnen sagen, jetzt.
Was es ist
Zunächst einmal, es ist eine SQL-basierte Zeitreihen-Datenbank von Grund auf für die Leistung aufgebaut. Es ist sehr große Datenmengen sehr schnell zu speichern und Abfrage erstellt.
Wir entfalteten sie auf einem AWS c5.metal Server in London, UK Rechenzentrum (sorry alle Nordamerikaner, gibt es einige eingebaute in Latenz aufgrund der Gesetze der Physik). Es wurde mit 196GB RAM konfiguriert, aber wir wurden mit 40GB nur bei Spitzenauslastung. Das c5.metal Beispiel stellt 2 24-Core-CPUs (48 Kerne), aber wir nur einer von ihnen (24 Kerne) verwendet, auf 23 Verknüpfungen. Wir waren mit wirklich nicht überall * schließen * auf das volle Potenzial dieser AWS-Instanz. Das hat offenbar keine Rolle.
Die Daten werden auf einem Datenträger gespeichert AWS EBS, die SSD-Zugriff auf die Daten bereitstellt. Es ist nicht alles im Speicher.
Die Daten sind die gesamte NYC Taxi-Datenbank sowie zugehörige Wetterdaten. Es beläuft sich auf 1,6 Milliarden Datensätze, in etwa 350 GB an Daten mit einem Gewicht. Das ist viel. Und es ist zu viel im Speicher zu speichern. Es ist zu viel zu Cache.
Wir stellten einige klickbare Abfragen Menschen zu erhalten begonnen (keines der Ergebnisse zwischengespeichert wurde, oder im Voraus berechnet), aber wir haben im Wesentlichen nicht die Art von Anfragen beschränken, dass die Nutzer laufen können. Wir wollten sehen, und lassen Sie Benutzer sehen, wie gut diese auf durchgeführt, was auch immer fragt sie warf.
Es war enttäuschend, nicht!
Der Hacker News Beitrag
Vor einigen Wochen schrieben wir darüber, wie wir SIMD-Befehle implementiert eine Milliarde Zeilen in Millisekunden [1] Dank im großen Teil auf Agner Fog VCL-Bibliothek [2] aggregieren. Obwohl der anfängliche Umfang Tisch weiten Aggregate zu einem einzigartigen skalaren Wert begrenzt war, war dies ein erster Schritt hin zu sehr die Ergebnisse auf komplexere Aggregationen viel versprechend. Mit der neuesten Version von QuestDB, erweitern wir dieses Leistungsniveau zu schlüsselbasierte Aggregationen.
Um dies zu tun, setzten wir schnell Hash-Tabelle von Google aka „Swisstable“ [3], die in der Abseil-Bibliothek gefunden werden können [4]. In aller Bescheidenheit, fanden wir auch Raum leicht es für unseren Anwendungsfall zu beschleunigen. Unsere Version von Swisstable wird genannt „Rösti“, nach dem traditionellen Schweizeren Gericht [5]. Es gab auch eine Reihe von Verbesserungen durch Techniken, die von der Gemeinschaft vorgeschlagen, wie Prefetch (die interessanterweise keine Auswirkung auf der Karte Code, wie ich heraus selbst) [6]. Neben C ++, haben wir unser eigenes Queue-System in Java geschrieben, um die Ausführung parallelisieren [7].
Die Ergebnisse sind bemerkenswert: Millisekunden Latenz auf verkeilten Aggregationen dass Spanne über Milliarden von Zeilen.
Wir dachten, es ist eine gute Gelegenheit, unsere Fortschritte zu zeigen, könnte diese neueste Version zur Verfügung, indem sie online mit einem vorinstallierten Datensatz zu versuchen. Es läuft auf einem AWS Beispiel 23 unter Verwendung von Fäden. Die Daten werden auf der Festplatte gespeichert und enthalten eine Reihe 1,6Mrd NYC Taxi-Datensatz, 10 Jahre von Wetterdaten mit rund 30-minütigen Auflösung und Wochengaspreise im letzten Jahrzehnte. Die Instanz befindet sich in London, so Leute außerhalb Europas können unterschiedliche Netzwerklatenzen auftreten. Die serverseitige Zeit wird als „Execute“ berichtet.
Wir bieten Beispielabfragen, um loszulegen, aber Sie werden ermutigt, sie zu ändern. Aber bitte beachten Sie, dass nicht jede Art der Abfrage schnell noch ist. Einige laufen noch unter einem alten Single-Thread-Modell. Wenn Sie eine dieser finden, werden Sie wissen: Es Minuten statt Millisekunden dauern. Aber denken Sie bei uns, das ist nur eine Frage der Zeit, bevor wir diese momentane als auch machen. Als nächstes wird in unserem Visier ist Time-Bucket-Aggregationen mit der SAMPLE BY-Klausel.
Wenn Sie bei der Prüfung interessiert sind, wie wir das getan haben, ist unser Code zur Verfügung Open-Source [8]. Wir freuen uns auf Ihr Feedback zu unserer bisherigen Arbeit zu erhalten. Noch besser ist, würden wir gerne mehr Ideen hören um die Leistung weiter zu verbessern. Auch nach Jahrzehnten in High Performance Computing, lernen wir etwas noch täglich neu.
[1]https://questdb.io/blog/2020/04/02/using-simd-to-aggregate-b?ref=davidgsiot …
[2]https://www.agner.org/optimize/vectorclass.pdf
[3]https://www.youtube.com/watch?v=ncHmEUmJZf4
[4]https://github.com/abseil/abseil-cpp
[5]https://github.com/questdb/questdb/blob/master/core/src/main …
[6]https://github.com/questdb/questdb/blob/master/core/src/main …
[7]https://questdb.io/blog/2020/03/15/interthread?ref=davidgsiot
Und dann konnten wir den Link zur Live-Datenbank.
Und lehnte sich zurück.
Und den eingehenden Datenverkehr überwacht.
Und versuchte, nicht in Panik zu geraten.
Was ist passiert
Zunächst einmal haben wir die Titelseite der Hacker News. Dann blieben wir dort. Stundenlang*.
Wir sahen eine Menge Verkehr. Ich meine, eine * Menge * Verkehr. Irgendwo über 20.000 eindeutige IP-Adressen.
Ohne einfachen show Abfragen, sahen wir 17.128 SQL-Abfragen mit 2485 Syntaxfehler in den Abfragen. Wir schickten wieder fast 40 GB Daten in Reaktion auf die Anfragen. Die Reaktionszeiten waren phänomenal. Unter zweiten Antworten auf fast alle Abfragen.
Jemand in den HN Kommentare vorgeschlagen, dass Spalte speichert schlecht sind beitritt, was führte zu jemand kommen und versuchen, die Tabelle mit sich selbst zu verbinden. Normalerweise würde dies eine erstaunlich schlechte Entscheidung sein.
Das Ergebnis war … nicht, was sie erwartet hatten:
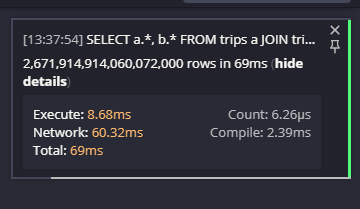
Ja, das ist 2.671.914.914.060.072.000 Reihen. In 69ms (einschließlich Netzwerk-Transferzeit). Das ist eine Menge von Ergebnissen in einer sehr kurzen Zeit. Auf jeden Fall nicht das, was sie erwartet haben.
Wir sahen nur ein paar schlechte Schauspieler versuchen, etwas süß:
2020-06-23T20:59:02.958813Z I i.q.c.h.p.JsonQueryProcessorState [8536] exec [q='drop table trips']
2020-06-24T02:56:55.782072Z I i.q.c.h.p.JsonQueryProcessorState [6318] exec [q='drop *']
Diejenigen aber, hat nicht funktioniert. Wir können verrückt sein, aber wir sind nicht naiv.
Was wir gelernt
Es stellt sich heraus, dass, wenn Sie etwas tun, man viel lernen. Sie lernen, Ihre Stärken und Ihre Schwächen. Und Sie erfahren, was die Nutzer wollen mit Ihrem Produkt zu tun, als auch, was sie tun werden, um zu versuchen, es zu brechen.
Die Teilnahme am Tisch selbst war eine solche Lektion. Aber wir sahen auch eine Menge Leute verwenden, um eine where Klausel, die ziemlich langsam Ergebnisse verursacht. Wir waren von diesem Ergebnis nicht völlig überrascht, als wir uns bewusst sind, dass wir nicht die Optimierungen auf diesem Weg die schnellen Ergebnisse zu erhalten getan haben wir wollen. Aber es war ein großer Einblick, wie oft sie benutzt wird, und wie die Menschen es nutzen.
Wir sahen eine Reihe von Menschen byKlausel, um dieGruppe als auch verwenden, und dann überrascht sein, dass es nicht funktioniert hat. Wir haben wahrscheinlich die Menschen sollten darüber gewarnt. Kurz gesagt: Gruppe by automatisch geschlossen wird, so ist es nicht erforderlich. Aber da ist es gar nicht umgesetzt, verursacht es einen Fehler. Also sind wir nach Wegen suchen, zu behandeln.
Wir nehmen alle diese Lektionen zu Herzen, und Pläne zur Adresse alles, was wir in den kommenden Versionen gesehen.
Schlussfolgerungen
Es scheint, dass die überwiegende Mehrheit der Menschen, die die Demo ausprobiert wurden damit sehr beeindruckt. Die Geschwindigkeit ist atemberaubend wirklich.
Hier sind nur einige der Kommentare, die wir im Thread bekommen:
I missbraucht LEFT eine Abfrage zu erstellen, die JOIN 224.964.999.650.251 Zeilen erzeugt. Nur 3.68ms Zeitausführung, nun, das ist beeindruckend!
Sehr cool. Wichtige Requisiten dies für die Umsetzung gibt und beliebige Abfragen zu akzeptieren.
Sehr beeindruckend, ich denke, ist Ihre eigene (performant) Datenbank von Grund auf neu bauen eines der beeindruckendsten Software Ingenieurleistungen.
Sehr cool und beeindruckend !! Ist voll PostreSQL Draht Kompatibilität auf der Roadmap? I wie Postgres Kompatibilität :)
(Ja, voll PostgreSQL Wire Protocol ist auf der Roadmap!)
Überwältigendes, wusste nicht, über questDB. Die Zurück-Taste erscheint auf Chrom Handy gebrochen
Ja, hat die Demo auf die Schaltfläche Zurück in Ihrem Browser nicht brechen. Es gibt einen tatsächlichen Grund dafür, aber es ist wahr, denn jetzt. Wir Adressierung auf jeden Fall, dass man sofort.
Versuch es selber
Wollen Sie es selbst versuchen? Sie haben bis hierher gelesen, sollten Sie wirklich! müssenhttp://try.questdb.io:9000/ gibt ihm einen Wirbel.
Wir würden uns freuen Sie uns gemeinsam haben, auf unsere Community Slack Channel, rufen Sie uns), rufen Sie uns Star auf GitHub und) und Download und versuchen sie es selbst!