
David G. Simmons
Donnerstag, 5. Dezember 2019
„IoT Daten aus anderen Quellen MySQL“
Wenn Sie eine IoT-Lösung im Einsatz haben, haben Sie zu entscheiden haben, wo und wie alle Ihre Daten zu speichern. Zumindest aus meiner Sicht der beste und einfachste Ort, um die Sensordaten zu speichern, ist natürlich, InfluxDB. Mein dass sagen kann als eine Überraschung für Sie nicht kommen. Aber was ist mit den anderen * * Daten müssen Sie speichern? Die Daten * über * die Sensoren? Dinge wie die Sensorhersteller wurden das Datum es in Betrieb genommen, der Kunden-ID, welche Art von Plattform, auf es läuft. Sie wissen, alle Sensor-Metadaten.
Eine Lösung, natürlich, ist es, einfach hinzufügen alle das Zeug als Tags zu Ihren Sensordaten in InfluxDB und geht über den Tag. Aber glauben Sie wirklich * * wollen alle Daten Ihres Sensors mit jedem Datenpunkt speichern? Viele Dinge scheinen wie eine gute Idee zu der Zeit, aber dann zufallen schnell in eine schreckliche Idee, wenn die Wirklichkeit trifft. Da die meisten dieser Metadaten oft nicht ändern, und auch mit Kundeninformationen in Verbindung gebracht werden kann, ist der beste Platz für sie sehr wahrscheinlich in einem traditionellen RDBMS. Wahrscheinlich bereits Sie * haben * ein RDBMS mit Kundendaten in ihr, warum also nicht nur um Hebelwirkung weiter, dass die Investitionen? Wie ich wiederholt gesagt habe, das ist ** nicht ** der beste Platz für Ihre Sensordaten. So, jetzt haben Sie Ihre IoT Daten in zwei verschiedenen Datenbanken einsehen. Wie greifen Sie es und führen Sie sie in einem Ort, wo man alles sehen kann?
Flux ist die Antwort
Sag mir, haben Sie das zu kommen. Sie haben das zu kommen gesehen haben. Ok, um fair zu sein, können Sie haben, denn nach allem, wie werden Sie Ihre SQL-basierten Daten über Flux zu bekommen? Das ist die Schönheit von Flux: es ist erweiterbar! Also haben wir jetzt eine Erweiterung haben, dass Sie Daten von jeder MySQL, MariaDB oder Postgres über Flux lesen können. Als ich hörte, dass dieser SQL-Anschluss war bereit zu gehen, ich kann es nur versuchen musste. Ich werde Ihnen zeigen, was ich gebaut, und wie.
eine Kundendatenbank bauen
Das erste, was zu tun war, eine MySQL-Datenbank mit einigen Kundeninformationen aufzubauen. Ich habe eine neue Datenbank mit dem Namen IoTMeta, in die ich mit einigen Sensor Metadaten einen Tisch setzen. Ich habe auch eine andere Tabelle mit Kundeninformationen über diese Sensoren.

Ziemlich einfach Tabellen, wirklich. entsprechend den Sensor_id Tag in meinem InfluxDB Beispiel die Sensor_ID Feld I mit Daten gefüllt. Ich wette, Sie können sehen, wo ich mit diesem bereits gehe. Ich habe eine Reihe von Daten:

So, jetzt meine Sensor-Metadaten-Datenbank hat einige Informationen über jeden Sensor ich hier ausgeführt wird, sowie einige ‚Kundendaten‘ darüber, wer die Sensoren besitzt. Jetzt ist es Zeit nützlich dies alles in etwas zu ziehen.
abfragen, um die Daten mit Flux
Zuerst baute ich eine Abfrage in Flux einige meiner Sensordaten zu bekommen, aber ich war in den Sensordaten selbst nicht wirklich interessiert. Ich war auf der Suche nach einer Identifizierung Tag Wert: Sensor_id. Diese Abfrage wird ein wenig seltsam aussehen, aber es wird Sinn am Ende machen, das verspreche ich.
temperature = from(bucket: "telegraf")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r._measurement == "temperature" and (r._field == "temp_c"))
|> last()
|> map(fn: (r) => {
return { query: r.Sensor_id }
})
|> tableFind(fn: (key) => true) |> getRecord(idx: 0)
Es gibt eine Tabelle von einer Zeile, und dann den Sensor_id Tag zieht, und das ist, wo Sie wahrscheinlich da sagen„Whaaaat?“ Denken Sie daran: Flux alles in Tabellen zurückgibt. Was ich brauche, ist im Wesentlichen ein skalaren Wert aus dieser Tabelle. In diesem Fall ist es ein String-Wert für den Tag in Frage. Das ist, wie Sie das tun.
Als nächstes werde ich den Benutzernamen und das Passwort für meine MySQL-Datenbank erhalten, die bequem in der InfluxDB Secrets Speicher gespeichert wird.
uname = secrets.get(key: "SQL_USER")
pass = secrets.get(key: "SQL_PASSW")
Warten Sie, wie bin ich diese Werte in diese Geheimnisse sowieso lagern? Rechts, lassen Sie uns eine Minute sichern.
curl -XPATCH http://localhost:9999/api/v2/orgs/<org-id>/secrets -H 'Authorization: Token <token>' -H 'Content-type: application/json' --data '{ "SQL_USER": “<username>" }'
Eine Sache zu beachten ist, dass Sie das bekommen <org-id> Aus Ihrer URL. Es ist ** nicht ** der tatsächliche Name Ihres Unternehmens in InfluxDB. Dann tun Sie das Gleiche für das SQL_PASSW Geheimnis. Sie können sie etwas rufen Sie wirklich wollen. Jetzt müssen Sie nicht Ihren Benutzername / Passwort im Klartext in der Abfrage setzen.
Als nächstes werde ich all das verwenden, um meine SQL-Abfrage zu erstellen:
sq = sql.from(
driverName: "mysql",
dataSourceName: "${uname}:${pass}@tcp(localhost:3306)/IoTMeta",
query: "SELECT * FROM Sensor_data, Customer_Data WHERE Sensor_data.Sensor_ID = ${"\""+temperature.query+"\" AND Sensor_data.measurement = \"temperature\" AND Sensor_data.CustomerID = Customer_Data.Customer_ID"}" //"SELECT * FROM Sensor_data WHERE Sensor_ID = ${"\""+temperature.query+"\" AND measurement = \"temperature\""}" //q // humidity.query //"SELECT * FROM Sensor_Data WHERE Sensor_ID = \"THPL001\""// humidity.query
)
Sie werden sehen, dass ich den Wert von meiner ersten Flux-Abfrage in der SQL-Abfrage bin mit. Cool! Sie können auch feststellen, dass ich eine join, dass SQL-Abfrage so ist Ausführen dass ich Daten aus * beide * Tabellen in der Datenbank erhalten. Wie cool ist das? Als nächstes werde ich die resultierende Tabelle formatiert werden nur die Spalten I Anzeige haben wollen:
fin = sq
|> map(fn: (r) => ({Sensor_id: r.Sensor_ID, Owner: r._Sensor_owner, Manufacturer: r.Sensor_mfg, MCU_Class: r.MCU_class, MCU_Vendor: r.MCU_vendor, Customer: r.Customer, Address: r.Address, Phone: r.phone}))
Ich habe jetzt einen Tisch bekommt, dass alle Metadaten über meinen Sensor sowie alle Kundenkontaktdaten über diesen Sensor enthält. Es ist Zeit für etwas Magie:
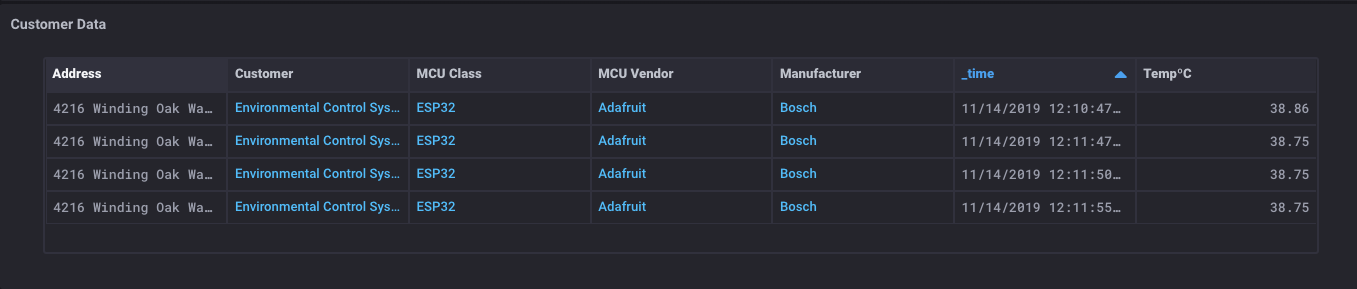
Was ist das für eine Zauberei? Ich habe eine Tabelle, die alle Metadaten über den Sensor, einige Kundendaten, ** und ** die Sensormesswerte zu hat? Ja. Ich mache. Und hier ist die wirklich magische Sache: Da Sie Daten aus beiden SQL-Datenbanken * und * InfluxDB Eimer bekommen, können Sie auch, dass die Daten in eine einzige Tabelle verbinden.
Hier ist, wie ich das getan hätte:
temp = from(bucket: "telegraf")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r._measurement == "temperature" and (r._field == "temp_c"))
Ruft mich eine Tabelle der Sensordaten. Ich habe bereits eine Tabelle der Metadaten von SQL, so …
j1 = join(tables: {temp: temp, fin: fin}, on: ["Sensor_id"] )
|> map(fn: (r) => ({_value: r._value, _time: r._time, Owner: r.Owner, Manufacturer: r.Manufacturer, MCU_Class: r.MCU_Class, MCU_Vendor: r.MCU_Vendor, Customer: r.Customer, Address: r.Address, Phone: r.phone}))
|> yield()
Ich schließe nur die beiden Tabellen auf einem gemeinsamen Element (das Sensor_id Feld), und ich habe eine Tabelle, die alles an einem Ort hat!
Es gibt eine Reihe von Möglichkeiten, dass Sie diese Möglichkeit, Daten aus verschiedenen Quellen zusammenführen können. Ich würde gerne hören, wie Sie so etwas wie dies umzusetzen wären besser auf Ihre Sensor-Implementierungen zu verstehen.
Ich habe all dies die Alpha18 Build von InfluxDB 2.0 verwenden getan, das ist, was ich laufen - eigentlich habe ich meine Version aus dem master individuell bauen, weil ich einige Ergänzungen Flux haben, dass ich verwenden, aber das ist eine ganz andere Posten. Aus diesem Material baut sich die Alpha von OSS InfluxDB 2.0 gut funktionieren. Sie sollten es unbedingt ausprobieren!